
Introduction
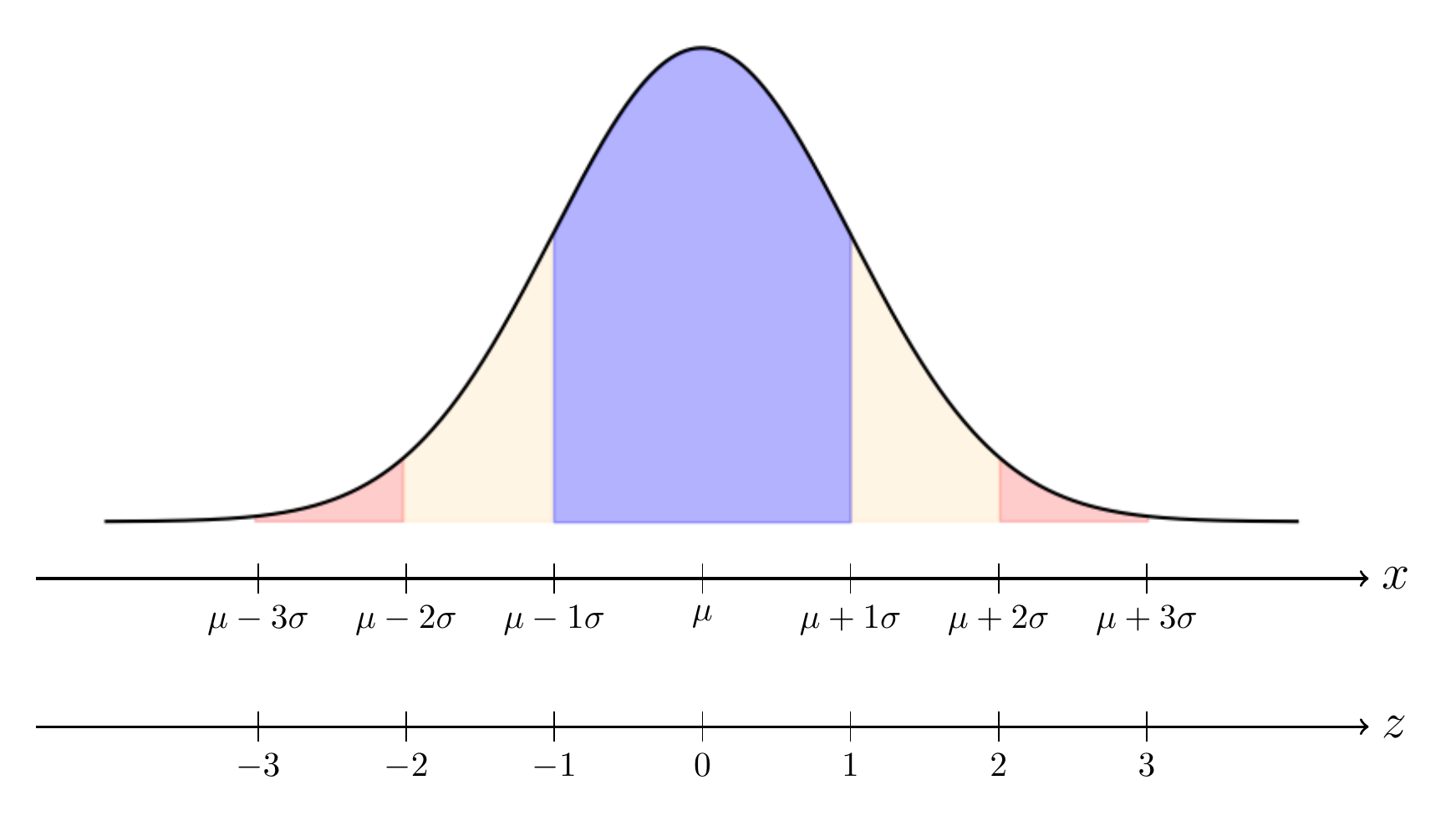
New students in science and mathematics may have seen a figure such as the one below.
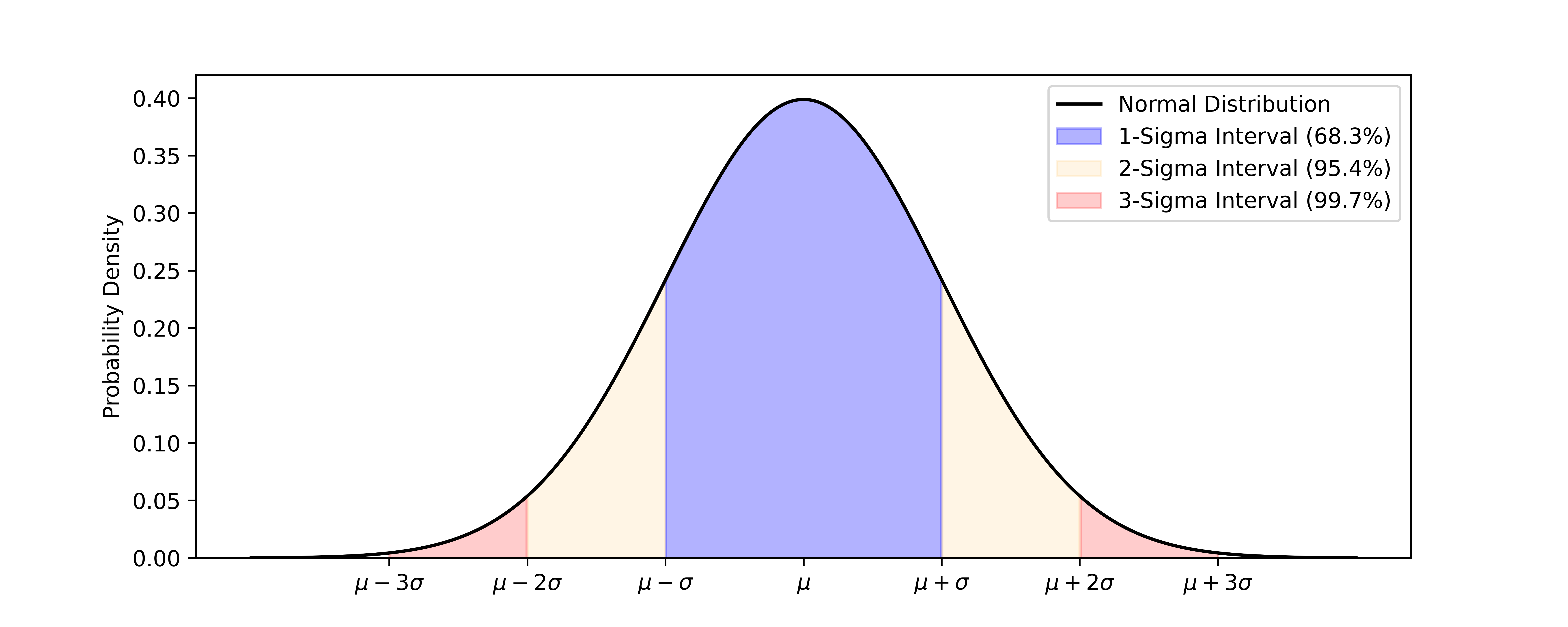
This figure illustrates the normal distribution, also known to as the Gaussian distribution, which is a fundamental concept in statistics and probability theory. The normal distribution is characterized by its bell-shaped curve, as we can see above, that is symmetric around its mean, , and has a “bandwidth” proportional to the parameter , whose square is the variance. The form of the curve above is written as
with meaning “defined to be equal to”. As the number of variables sampled from the normal distribution increases, their standard deviation converges to . Therefore, though technically an oversimplification, is commonly referred to as the distribution’s standard deviation.
Often, the explanations following the graph and equation above say that a variable following a normal distribution will have:
- probability of being within (1 interval),
- probability of being within (2 interval),
- probability of being within (3 interval).
However, more often than not, this is not proven or justified when it is first presented. It is taken for granted that students will immediately understand the normal distribution, to the point that the notation is taught in the first experimental physics course with even less context than what was written so far. The natural question is: WHY? why is the normal distribution so important? and can where does the rule comes from?
Here I will do my best to further demystify the normal distribution and its properties in a way that is accessible to a young scientist such as someone who is just starting their first course on calculus. In particular by answering the second question in the previous paragraph, I will present a method that allows one to calculate the probability of any interval, rather than only within ,, or .
Why is the normal distribution so important?
I am pretty \( \LARGE \frac{1}{\sqrt{2\pi \sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} \) . Are you \( \LARGE \frac{1}{\sqrt{2\pi \sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} \) ?
Prof. Steve Pressé, PI of Pressé Lab
As a brief example of a real-world quantity following the normal distribution, we use the mass of penguins obtained using the penguins dataset, accessible through the seaborn library. For further details on data collection, refer to the Palmer Penguins repository. In this instance, we will examine the distribution of mass among male penguins of the “gentoo” species, highlighting its approximation to a normal distribution.
import numpy as np
import seaborn as sns
penguins = sns.load_dataset("penguins")
mass = (penguins[np.logical_and(penguins['sex']=='Male', penguins['species']=='Gentoo')]['body_mass_g']).to_numpy()
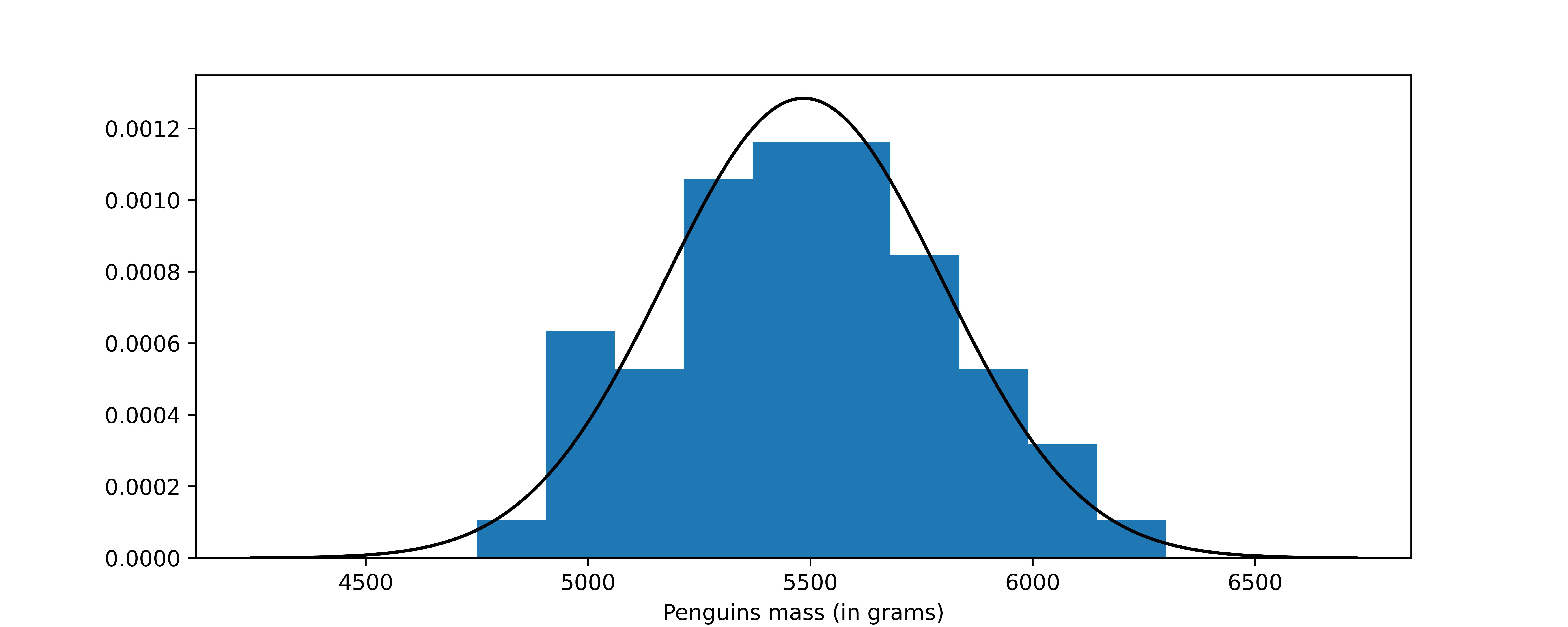
For the full code generating the figure below, the code generating my blogs is available in my GitHub repository
Upon examining the plot, several questions may emerge. While the normal distribution appears to be a reasonable approximation, deviations, particularly at lower masses, are noticeable. This discrepancy could be attributed to the limited size of the dataset, which comprises only 61 male gentoo penguins. This observation raises the question of whether this variable truly follows a normal distribution.
It is, nevertheless, common practice to assume that many datasets will follow the normal distribution. Such assumption is often justified by the central limit theorem, which states that the sum of a large number of independently distributed random variables, each with finite mean and variance, will be approximately normally distributed, regardless of the underlying distribution. This theorem is a cornerstone of statistics because it implies that methods that work for normal distributions can be applicable to many problems involving other types of distributions. It is still relevant, however, to verify if the conditions of the central limit theorem are valid, as failing to do so can lead to drastically incorrect results.
Although it is not my goal to explain the central limit theorem in detail, we can illustrate its significance through programming with random variables. First, let us sample a large number of values uniformly distributed between and , draw its histogram, and compare it to the normal distribution with the same mean and variance.
np.random.seed(42)
sam = np.random.uniform(size=10000)
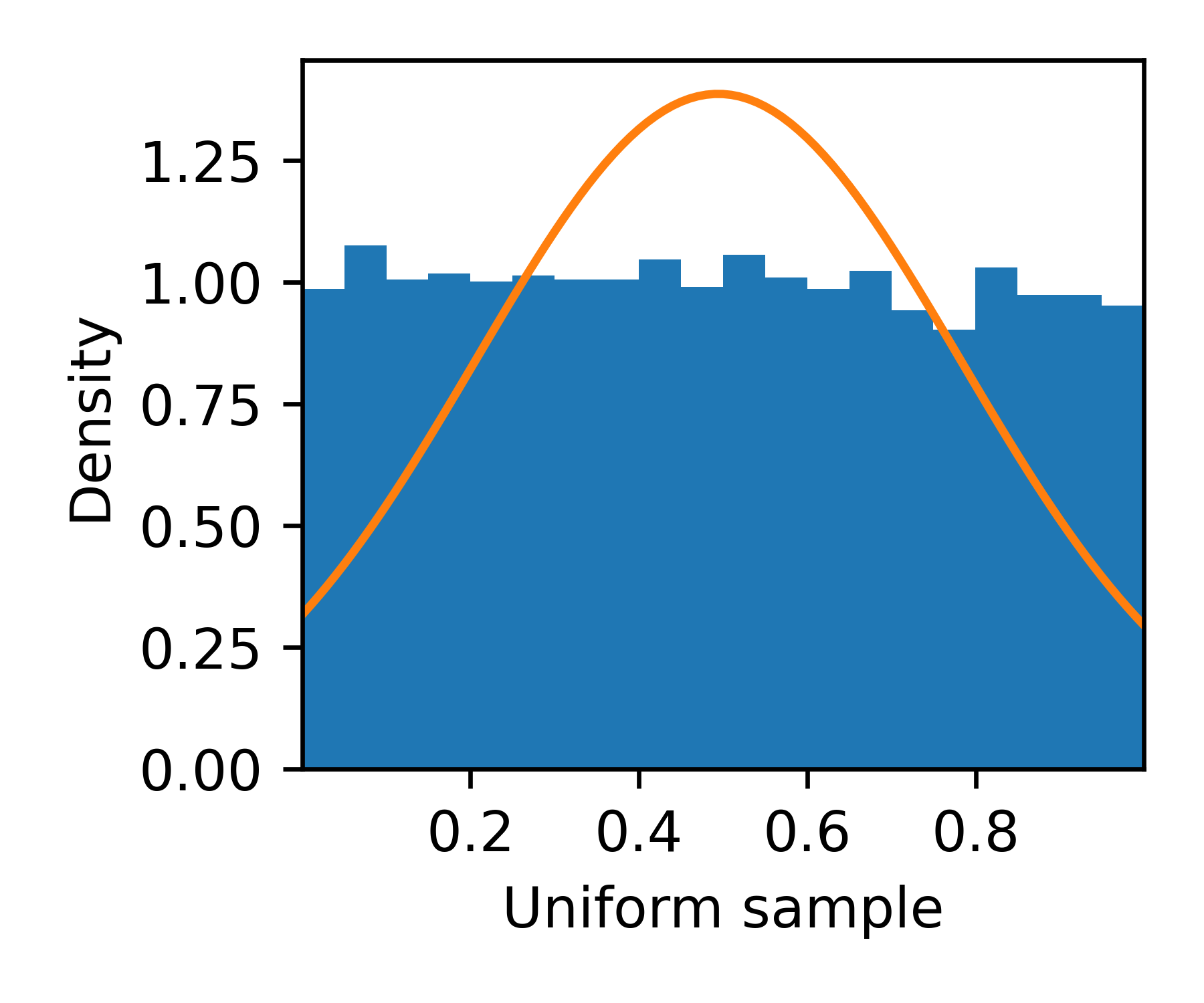
This is not a good fit, however, let us observe the same visualization for the sum of two independent uniformly sampled values.
sam2 = np.random.uniform(size=10000)
sam_sum = sam+sam2
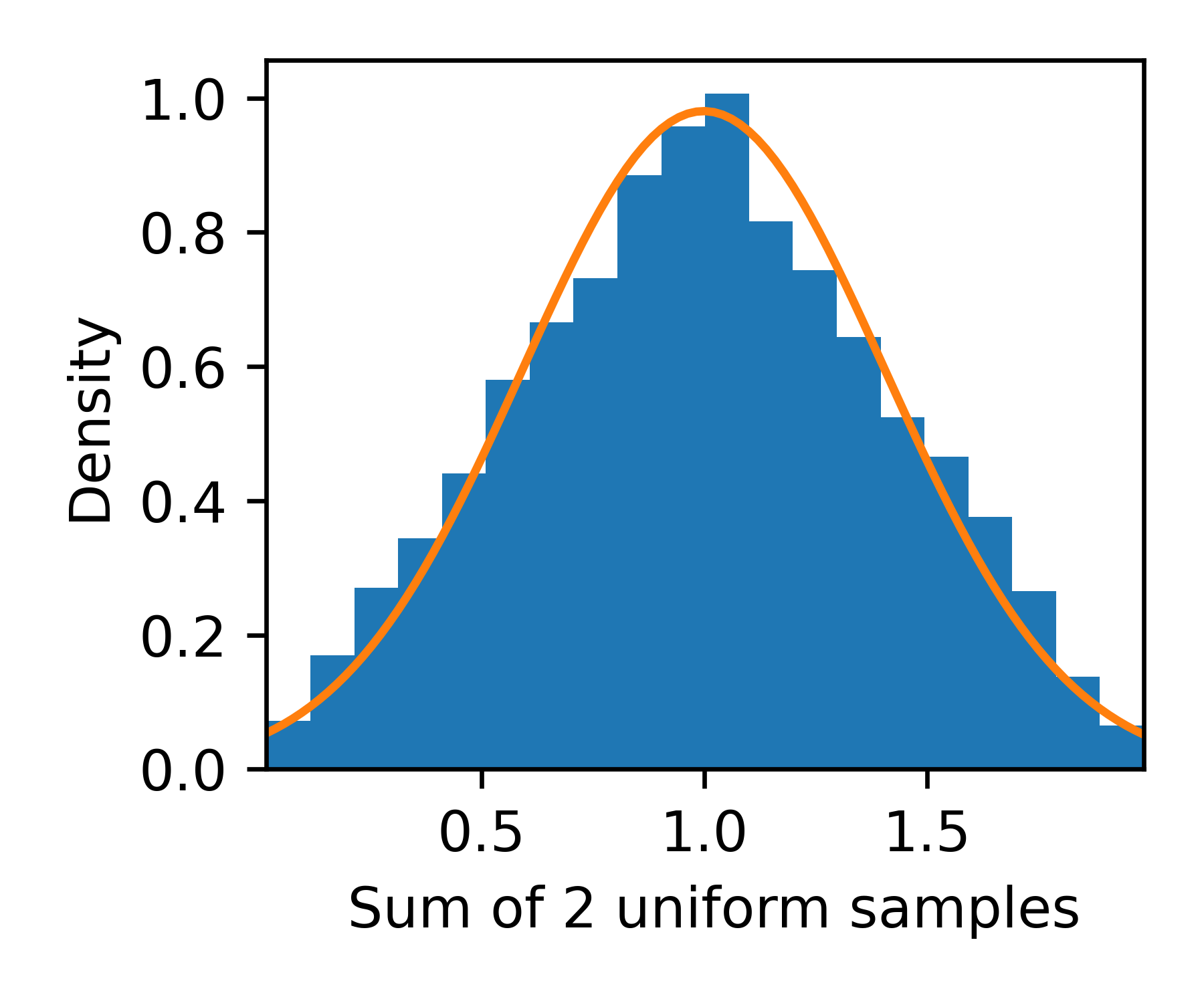
Here, we notice that the fit to a normal distribution is considerably better, and it improves as we consider the sum of a larger number of independently and identically distributed variables.
sam = np.vstack((sam,sam2,np.random.uniform(size=(6,10000))))
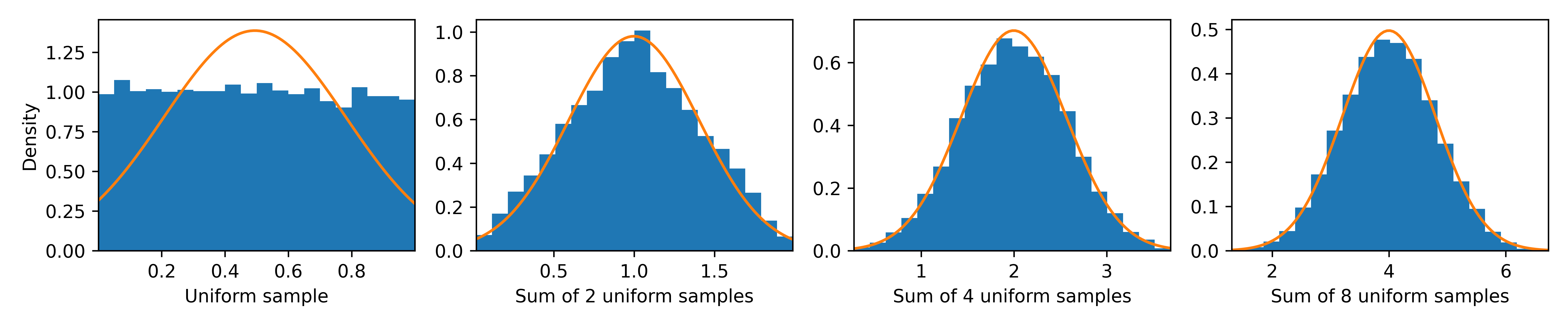
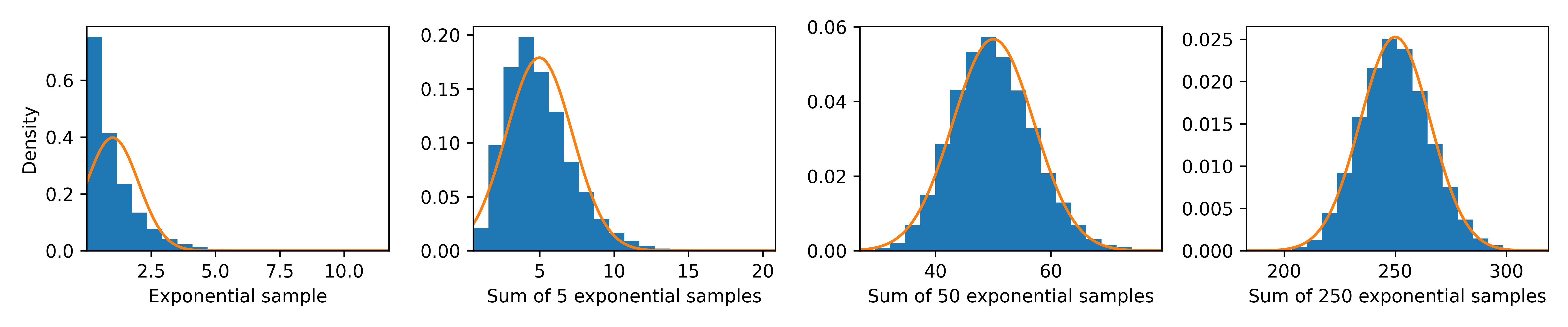
Now, to demonstrate that this phenomenon is not exclusive to uniformly distributed values, we observe a similar approximation to the normal distribution using plots for the sum of exponentially distributed values.
sam_exp = np.random.exponential(size=(250,10000))
In real-world scenarios, the argumentation becomes slightly more complex. However, we can imagine that some macroscopic variables, such as the mass and height of animals, are built upon the accumulation of a large number of small changes and, as such, could be approximated by a normal distribution. Similarly, the diffusion of objects observed in phenomena like Brownian motion results from the sum of numerous small collisions. Each of these collisions, though random and independent, collectively contributes to a movement pattern that, over time, can be described by a normal distribution. This demonstrates that whether we are examining physical phenomena at a microscopic level or looking at larger, more complex systems, the central limit theorem provides a powerful tool for understanding the underlying distributions that govern these processes.
Where does the rule comes from? Integrating the normal distribution
All a physicist needs to know is how to integrate Gaussians.
Prof. Renato Vicente, my undergraduate instructor of numerical analysis
The significance the normal distribution often becomes nebulous even for experienced scientists in some fields. Eq. (1) represents the probability density, indicating how likely it is to obtain a value at any point along the -axis. The area under the curve, in other words the integral, corresponds to the probability of observing a value within a certain range. In calculus terms, we would say that the probability for a variable that follows the normal distribution to be observed within an interval is given by
Note that we use capital to represent the probability of the interval (the integral) while is reserved for the probability density (integrand).
The standard normal
To calculate the integral in (2), a useful trick is to transform from to , where is defined as
From this, we can express the probability of an interval in terms of instead of . Let us see what this change of variables from to does in the illustration below
Transforming the probability accordingly means that, for whichever interval we must have
or, equivalently,
Through calculus considerations, this means that the probability density for is obtained as
leading to a of the form
In summary, defined in (3) has normal distribution with mean 0 and variance 1.
Due to the importance of this trick, is often termed the standard normal.
Thus, with the transformation of in hands, we can return to the question of finding what if the probability of being within the interval as
However, despite the simplification given by the trick, the challenge continues because there is no analytic, closed-form expression for the integral of .
Error function
Despite having no closed-form analytic expression for the integral in (4), one way to obtain the probability through numerical methods involves defining the error function, denoted as , as
Most scientific calculations and numerical programing libraries provide a calculation of , for example in python one can use the scipy erf implementation. By substituting the error function in (4) we obtain the probability of an interval as
Now, it can be useful in many applications to work on symmetric intervals around the mean . Meaning, if can be written in the form ,
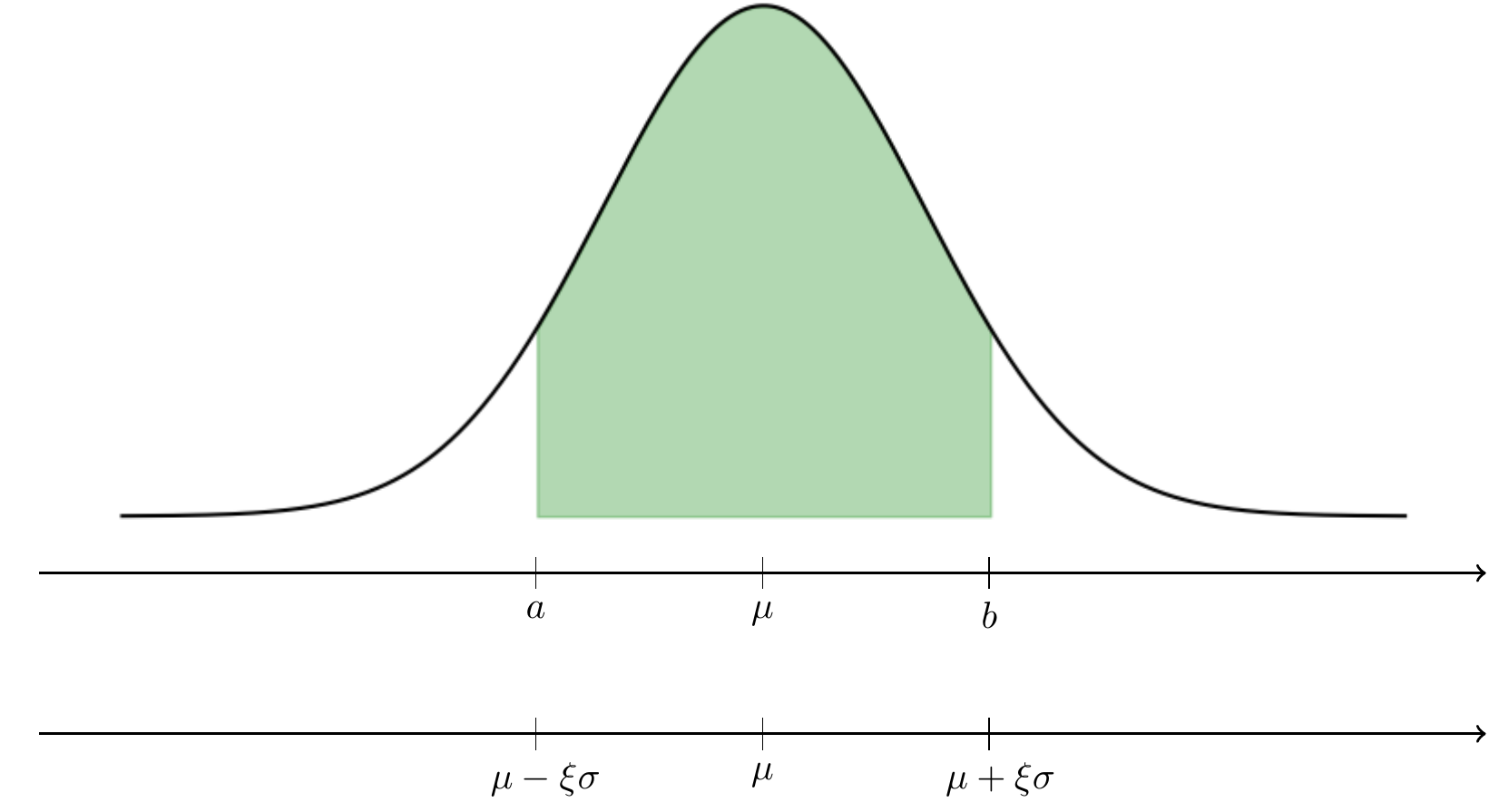
the set of such that is equivalent to the set for which . Thus we find the probability of a symmetric interval, from (6) as
Now, one can notice, from (5), that . Thus we have
Now, we can use the erf implementation to see what is the probability of these different intervals of varying . Let us see it in the form of a table
from scipy.special import erf
xi_full = np.arange(0, 4.1, 0.1)
xi_sqrt2_full = xi_full / np.sqrt(2)
erf_xi_full = erf(xi_sqrt2_full)
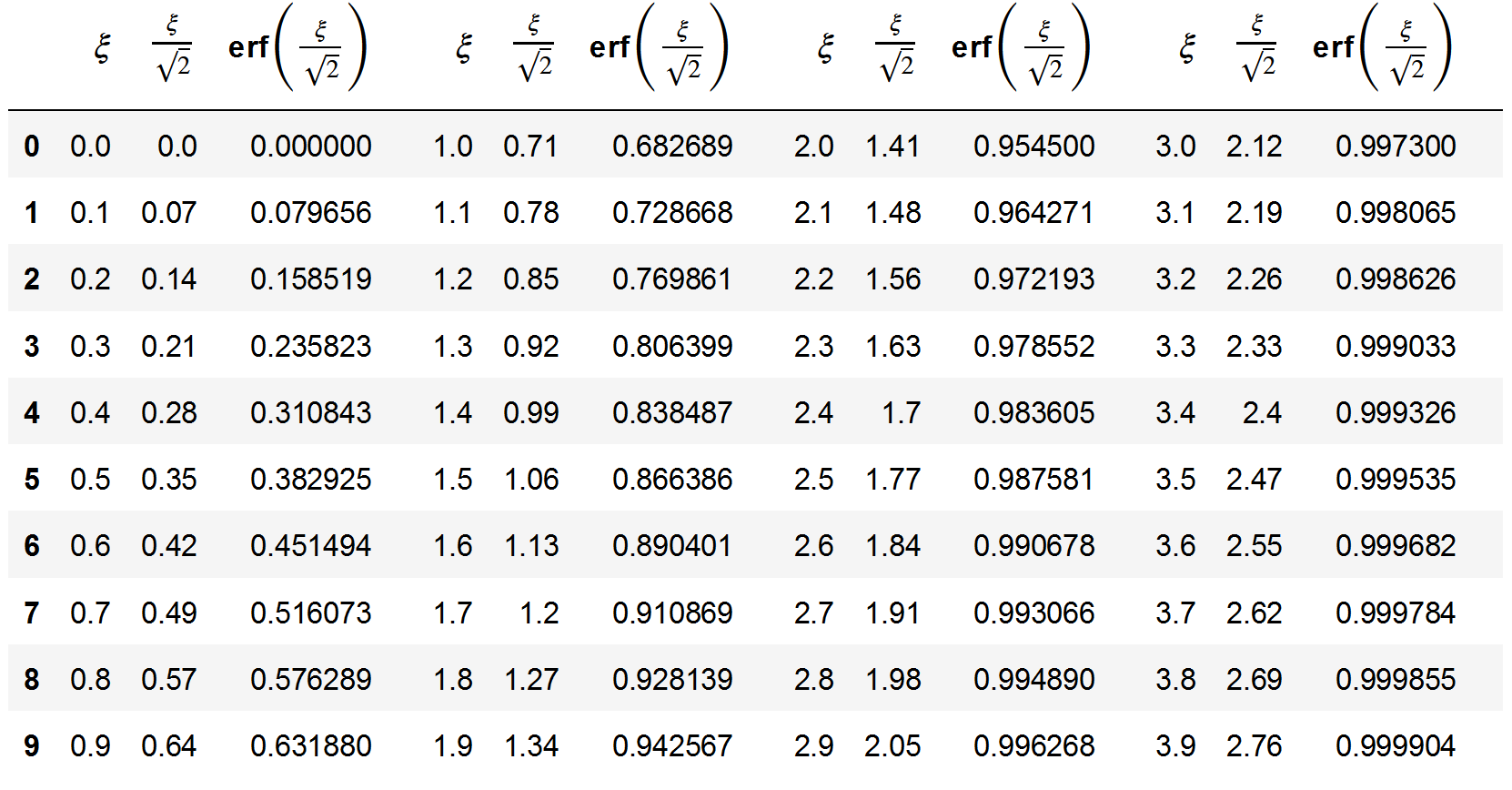
Examining the first row of the table above, we obtain the three values mentioned in the introduction, for , for , and for . In summary, the table above, as well as the equations (6) and (7) allow one to calculate the probability of any interval from a normally distributed variable.
Conclusion
In this blog post we can see a concise exploration of the normal distribution. First we have seen examples on how the sum of a large number of independent sampled variables (of other distributions) converges to a normally distributed variable. Because of this such we can expect a normal distribution whenever we observe the total sum of several small contributing factors.
Second, we have established the method for using the error function, , to evaluate the probability of specific intervals. This introduction scratches the surface of a topic of utmost importance across various fields of study. The normal distribution’s significance is universally acknowledged yet, beyond the familiar rule, which was derived here, a comprehensive justification are often reserved for advanced studies in college-level probability courses,
This discussion sets the stage for a deeper dive into error propagation and its role in general statistics. An aspect of science that is often severely overlooked. In the near future, posts will verse intricacies of how errors are compounded and analyzed in scientific research underscore the essence of understanding the normal distribution and related statistical tools. Stay tuned.
I would like to thank my colleagues Lance (Weiqing) Xu, Bruno Arderucio Costa, and Alan Boss for discussions leading to the writing of this post.
