
- The damped harmonic oscillator and its differential equation
- Some comments on the results
- When the neural network does not work
- Further reading
Neural networks have gathered enormous attention in the last decade. Our whole human community have been shocked with the ability to talk to ChatGPT and create convincing videos of Taylor Swift proving that is irrational, while also questioning the ethics behind their training schemes, and their ability to strengthen biases.
However, we don’t usually discuss the reason why neural networks work at all: they are universal approximators. This means they have the capacity to approximate any continuous function, given enough training and the appropriate architecture.
For that reason, neural networks can not only reproduce patterns image, voice, and text but also directly approximate solutions of well-posed mathematical problems. One area in which this is useful is solving differential equations.
As mathematicians and scientists are aware, besides the small class of linear ordinary differential equations there is no unified theory on how to solve them. In practice we usually try transform the differential equation in a system of ordinary differential equations using techniques, such as separation of variables, or by guesses (in current mathematical terminology Ansatz) from which the solution can be verified. However, there is no guarantees that it can work for an arbitrary differential equation.
In this post, I will show how to use a neural network to solve differential equations. This framework is usually referred to as physics-informed neural networks (PINNs). As the main example, we will work on a classic differential equation many physics students are familiar with: the damped harmonic oscillator.
While there are other good texts giving a similar lesson, often with the same example, from what I have gathered, they usually assume there is some form of data the neural network is supposed to fit.
In what follows, we will train a neural network that will only solve the mathematics involved in the differential equation.
Before anything else, let us setup the necessary libraries, here we will use PyTorch to implement our neural network.
import torch
import torch.nn as nn
torch.manual_seed(42)
import matplotlib.pyplot as plt
from math import pi
The damped harmonic oscillator and its differential equation
Suppose I have a system of a spring and a mass allowed to move on a table as in the figure below:
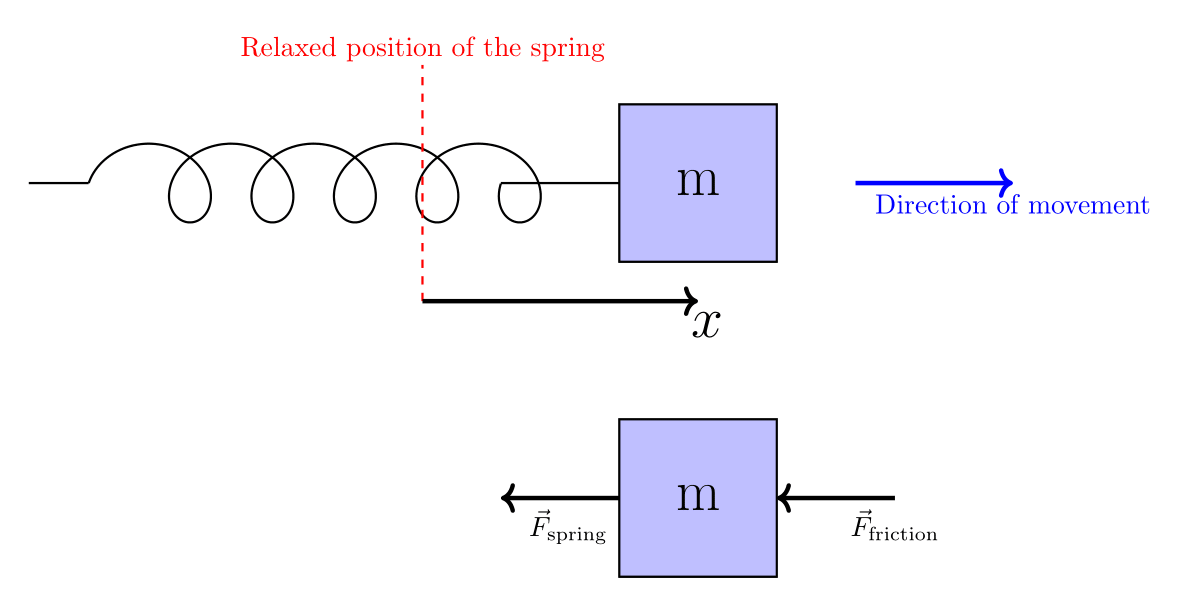
Say the mass is moved from the spring stable position by a displacement and released. We want to find how the position of the mass, , evolves in time.
Two forces act on the mass: the first is the restoring force from the spring, usually modeled through Hooke’s law as , with the sign representing that
the force is opposite to where the spring is pushed from its stable position, conventionally chosen as . Here we use the forces as scalar, as we constrain the mass to move within one dimension.
The other force is the friction opposing the movement . Although we refer to this as a friction force, this is not the friction model usually taught in early courses in physics but rather more akin to damping due to movement in a viscous fluid, with being the viscous damping coefficient. One can think on this more like air resistance than friction with the table surface.
Using Newton’s second law of motion, the total force, , is equal to mass times acceleration , allowing us to write the differential equation as
with some algebraic steps we can rewrite the equation above as
with and .
Say I push the spring and release it. Defining as the time at which the mass is released, the position at that time, and knowing that it was released from rest we can write
In the language of differential equations we say this is our initial condition. We say we solve the differential equation if we find , or the position of the mass as a function of time, that obeys both (2) and (3).
Solving the ‘underdamped’ case
First let us assume a case where . In rough terms, that means that the damping is weaker than the overall spring force. In other words, the system is underdamped. The next block of code will set what the variables of the problem:
x0 = 1.
w0 = 4*pi
xi = 2
Exact solution
In order to have something to compare our solution to, let us see if there are standard ways to solve (2) in the the underdamped condition. It has been proven (see e.g here, but it can be found in virtually any physics I textbook) that the exact solution is given by:
where . Note that the condition for the underdamped case, , is also the condition for to be real-valued (the quantity under the square root is positive).
w = torch.sqrt(torch.tensor(w0**2-xi**2/4 ))
x_sol_under= lambda t: x0*torch.exp(-.5*xi*t)*torch.cos(w*t)
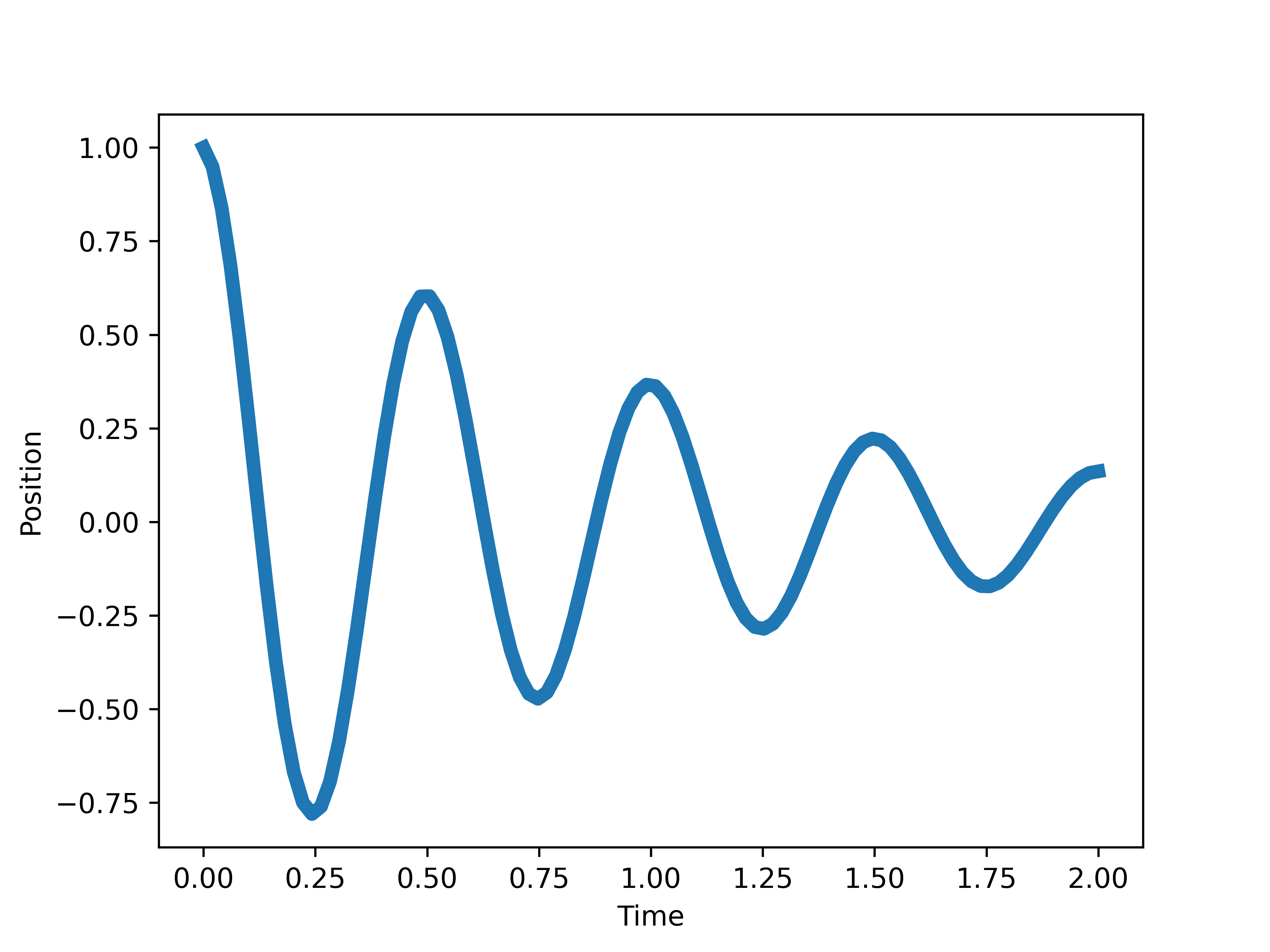
An attentive reader may notice through direct differentiating above that it, indeed, solves (2) and obeys (3). In the process they will notice how labourious it is to verify that ansatz, let alone come up with them. However we can intuit on its meaning. The solution is an oscillation, represented by the factor, and the oscillating amplitude decays exponentially as . This can be directly seen in the graph below
t = torch.linspace(0, 2, 100)[:, None]
plt.plot(t.numpy(),x_sol_under(t),linewidth=5)
plt.xlabel('Time')
plt.ylabel('Position')
Solving with neural network
If we want to solve the problem with neural networks, we need to start by defining our neural architecture. The goal is to use the neural network to creat a single-value function of time, , which we refer to as and use it to generate . Thus our architecture needs to map a single feature into (another) single feature but still have the necessary complexity to fit a complicated function. For this post we will use a sequential model composed of four linear layers. The architecture maps from 1 to 64 features, then from 64 to 256 features, followed by 256 to 64 features, and finally from 64 to 1 feature, with GELU activation.
architecture = lambda: nn.Sequential(nn.Linear(1, 64), nn.GELU(),
nn.Linear(64, 256), nn.GELU(),
nn.Linear(256, 64), nn.GELU(),
nn.Linear(64,1, bias=False))
N = architecture()
Now, as it is often the case with neural networks, it may be challenging to interpret what the neural network internal parameters do to solve the problem as a whole. Besides the architecture selection we have little control over what is initially. The goal, then, becomes to train the neural network to solve our differential equation (2) while obeying the initial condition (3).
In order to do so, it is useful to define the following function
with the symbol meaning ‘‘defined as equal to’’.
x_t = lambda t,N: x0+N(t)*(t**2)
Note that by definition we have and obeying the initial condition (3) no matter what the network is. The goal, then, is to train the neural network (change ) so that $ \tilde{x}(t)$ approximates the solution of the differential equation (2).
So, in order to train the neural network we ought to define a loss function to later be minimized. If is to approximate the solution of (2) we must have
at every time .
While it is hard to guarantee that the approximation above holds across a continuous interval, let us create an array of “test” times t of 500 points from to .
t = torch.linspace(0, 2, 500).reshape(-1,1)
Thus, within the interval we replace the approximation (5), taken for continuous time , by the saying that at each element in the array t we must have
For that, let us define the loss function as
Note that is strictly non-negative (it is a sum of squared terms), therefore its minumum possible value is 0, which would be equivalent obeying (3) at every test point in t.
It may look challenging to calculate the derivatives of inside , however this can be done straightforwardly, since neural network libraries usually contain tools to automatically calculate derivatives of a function. Here we use PyTorch’s autograd tool
def loss(t,N):
t.requires_grad = True
x = x_t(t,N)
dxdt = torch.autograd.grad(x,t, torch.ones_like(t), create_graph=True)[0]
d2xdt2 = torch.autograd.grad(dxdt,t, torch.ones_like(t), create_graph=True)[0]
loss_ode = d2xdt2 + xi*dxdt +(w**2)*x
return torch.mean(torch.pow(loss_ode,2))
We, then, train the network, meaning change the internal parameters within the network, in other words changing , so that takes smaller values, and say we are done training when the loss function is smaller than some threshold value (we use .1). This is done by the following block of code.
optimizer = torch.optim.Adam(N.parameters())
l = loss(t,N)
i=0
while l.item()>.1:
optimizer.zero_grad()
l = loss(t,N)
l.backward()
optimizer.step()
## Took around 1.5 mins in my machine
While it is not our goal to fully describe the training of neural networks, it is relevant to think more abstractly on what the previous block of code does. It identifies function , among the ones that can be generated by the architecture, that minimizes , and the generated from by (4) is the approximation of the differential equation’s solution. As such, let us visualize how well does our neural network solution compare to the known exact solution.
tt = torch.linspace(0, 2., 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N).numpy() #Neural
xt = x_sol_under(tt) #Exact
fig, ax = plt.subplots(dpi=100)
ax.plot(tt, xt, label='Exact', linewidth=5,alpha=.5)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
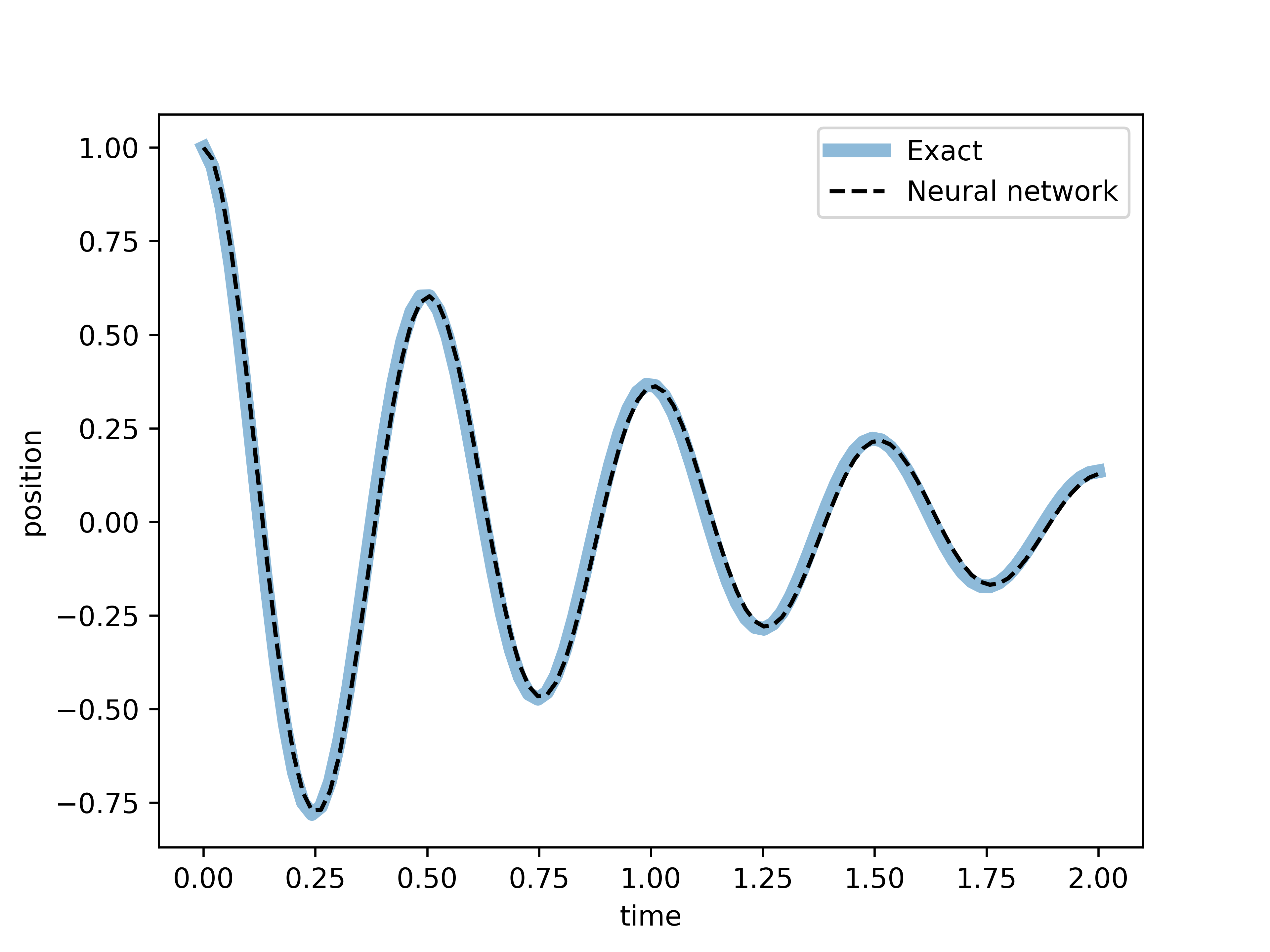
Now, as good as the result may look, so far we have only dealt with the underdamped case . But neural network training idea presented here can, indeed, be extended generally, as we will observe below.
Solving the ‘critically damped’ case
So far we worked on a case where . Let us observe how the solution changes, qualitatively, in the specific case where by directly solving this case using the neural network. First, let us define the parameters
w0_critical = 4*pi
xi_critical = w0_critical*2
and, initialize a new network N_critical and define a loss function with the new parameters.
N_critical = architecture()
def loss_critical(t,N):
t.requires_grad = True
x = x_t(t,N)
dxdt = torch.autograd.grad(x,t, torch.ones_like(t), create_graph=True)[0]
d2xdt2 = torch.autograd.grad(dxdt,t, torch.ones_like(t), create_graph=True)[0]
loss_ode = d2xdt2 + xi_critical*dxdt +(w0_critical**2)*x
return torch.mean(torch.pow(loss_ode,2))
We, then, repeat the training loop for this new network
optimizer_critical = torch.optim.Adam(N_critical.parameters())
l = loss_critical(t,N_critical)
i=0
while l.item()>.1:
optimizer_critical.zero_grad()
l = loss_critical(t,N_critical)
l.backward()
optimizer_critical.step()
and, once again, plot the result
tt = torch.linspace(0, 2., 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N_critical).numpy() #Neural
#xt = x_sol(tt) #Analitic
fig, ax = plt.subplots(dpi=100)
#ax.plot(tt, xt, label='Exact', linewidth=5,alpha=.5)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
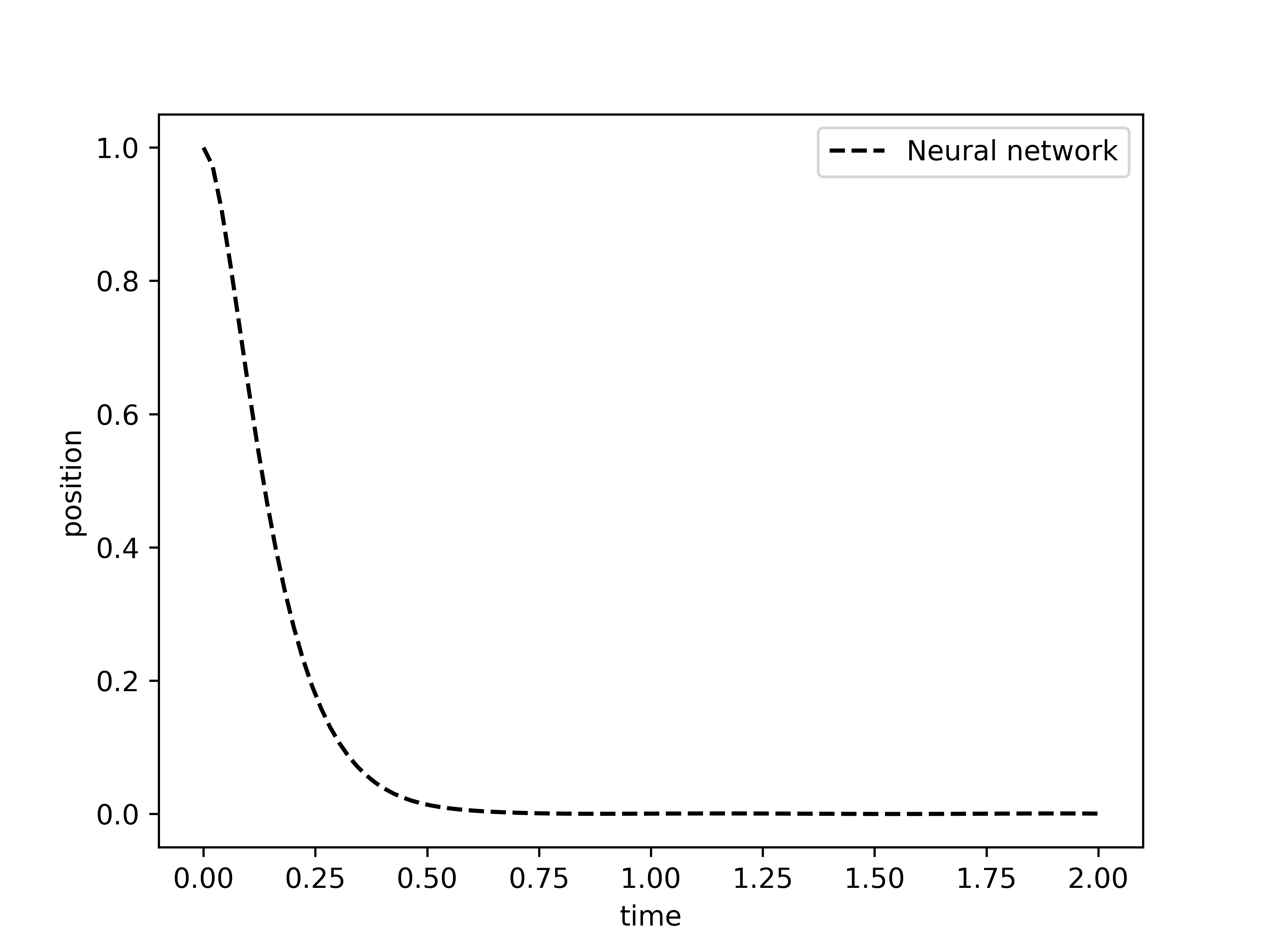
Note that, so far, we have not written the exact solution in this critically damped case, as it is not part of the neural network training at all. However, to test that neural network arrived at the correct solution, we write the exact solution, which is derived e.g. here which is given by
x_sol_critical = lambda t: x0*torch.exp(-.5*xi_critical*t)*(1+w0_critical*t)
Let us observe how the results compare to the exact solution
tt = torch.linspace(0, 2., 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N_critical).numpy() #Neural
xt = x_sol_critical(tt) #Analitic
fig, ax = plt.subplots(dpi=100)
ax.plot(tt, xt, label='Exact', linewidth=5,alpha=.5)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
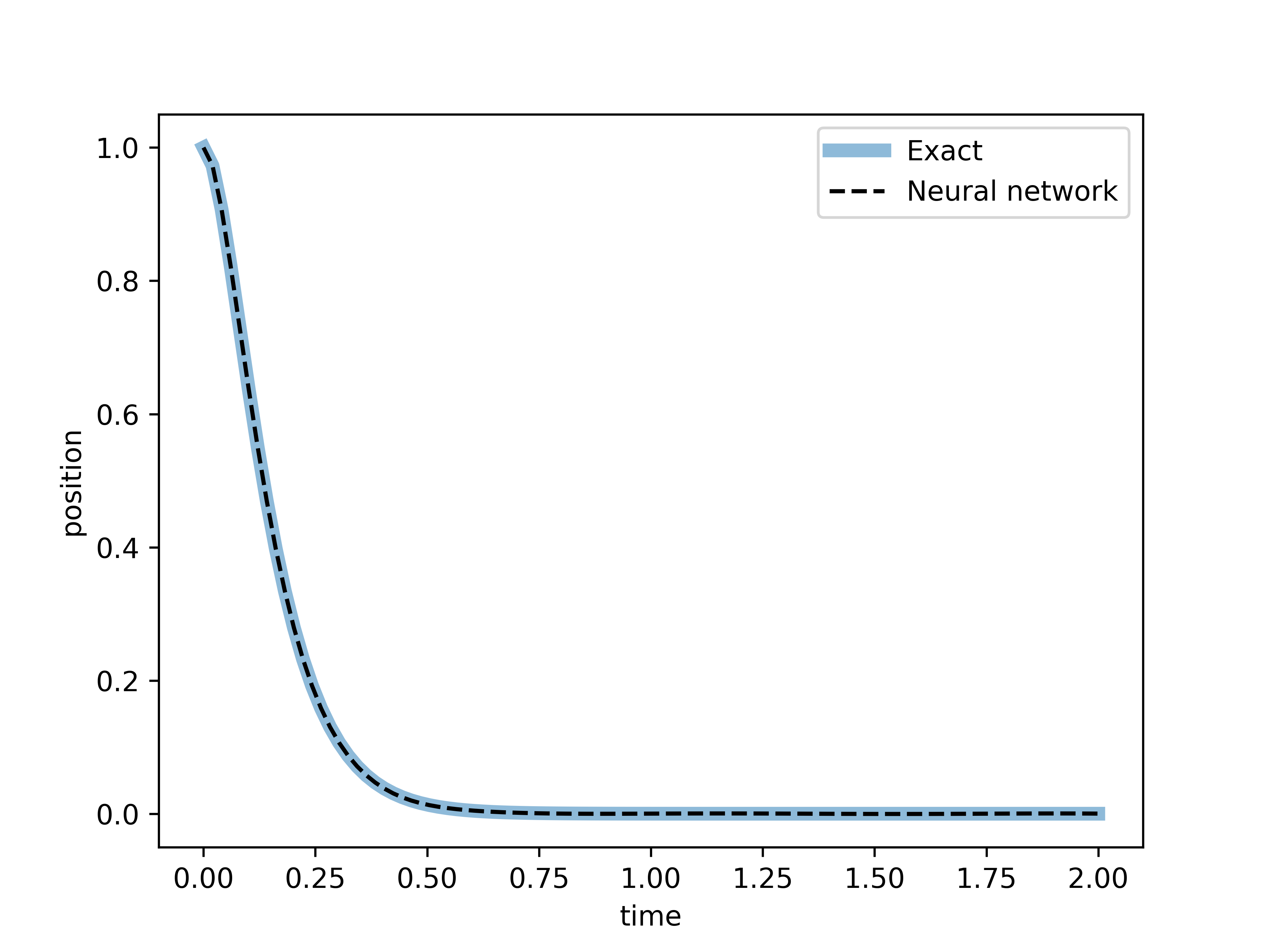
As with the underdamped case, in this critical case we also observe a near indistinguishable graph between the exact solution and the solution found by the neural network. Now, let us move forward into solve the equation in the overdamped case.
Solving the ‘overdamped’ case
Now let us move to the overdamped case, , by repeating the neural network procedure.
w0_over = 4*pi
xi_over = w0_over*4
and procede to define a new network an train it to solve the equation with new parameters
N_over = architecture()
def loss_over(t,N):
t.requires_grad = True
x = x_t(t,N)
dxdt = torch.autograd.grad(x,t, torch.ones_like(t), create_graph=True)[0]
d2xdt2 = torch.autograd.grad(dxdt,t, torch.ones_like(t), create_graph=True)[0]
loss_ode = d2xdt2 + xi_over*dxdt +(w0_over**2)*x
return torch.mean(torch.pow(loss_ode,2))
optimizer_over = torch.optim.Adam(N_over.parameters())
l = loss_over(t,N_over)
i=0
while l.item()>.1:
optimizer_over.zero_grad()
l = loss_over(t,N_over)
l.backward()
optimizer_over.step()
tt = torch.linspace(0, 2, 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N_over).numpy() #Neural
#xt = x_sol(tt) #Analitic
fig, ax = plt.subplots(dpi=100)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
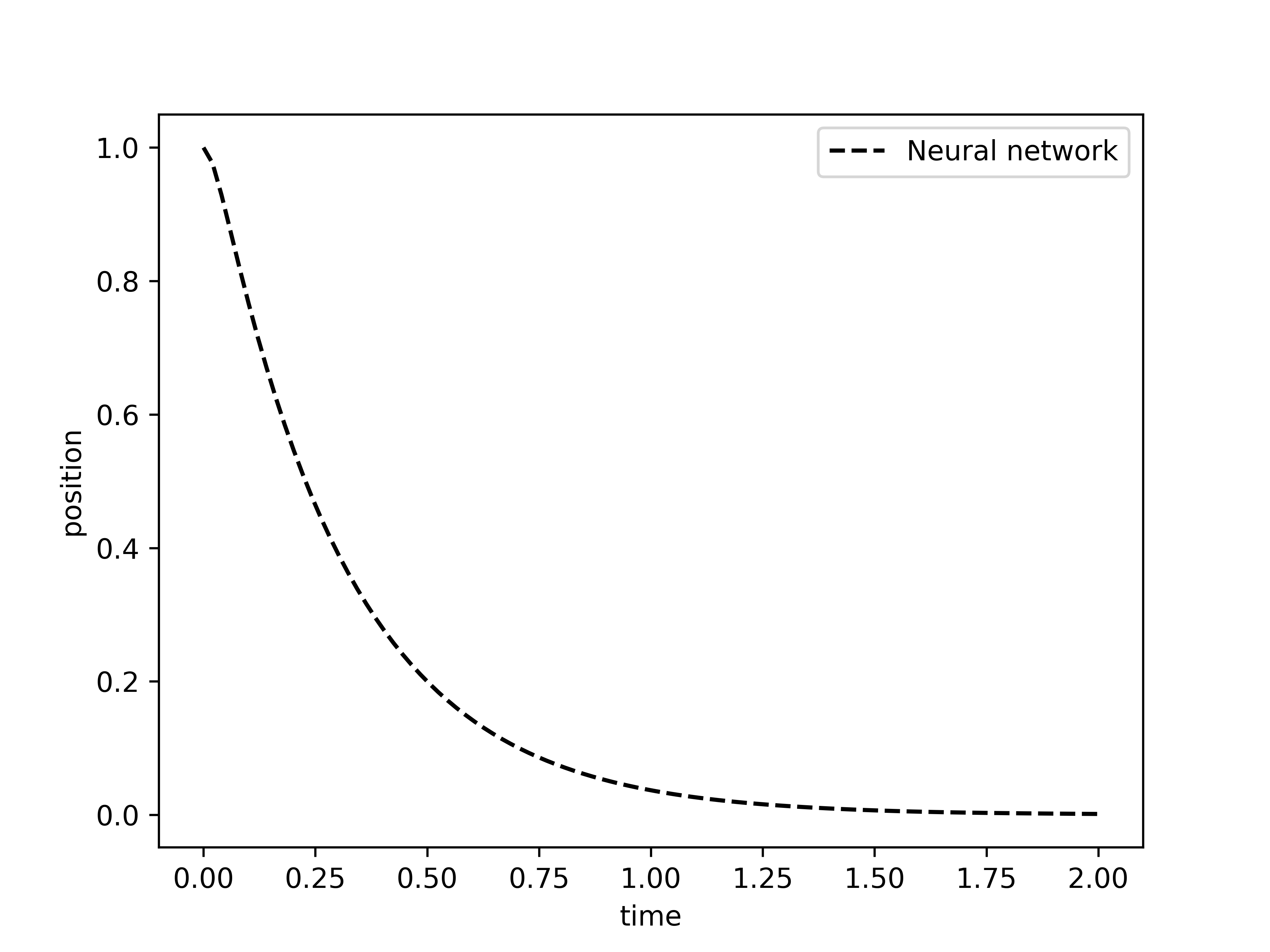
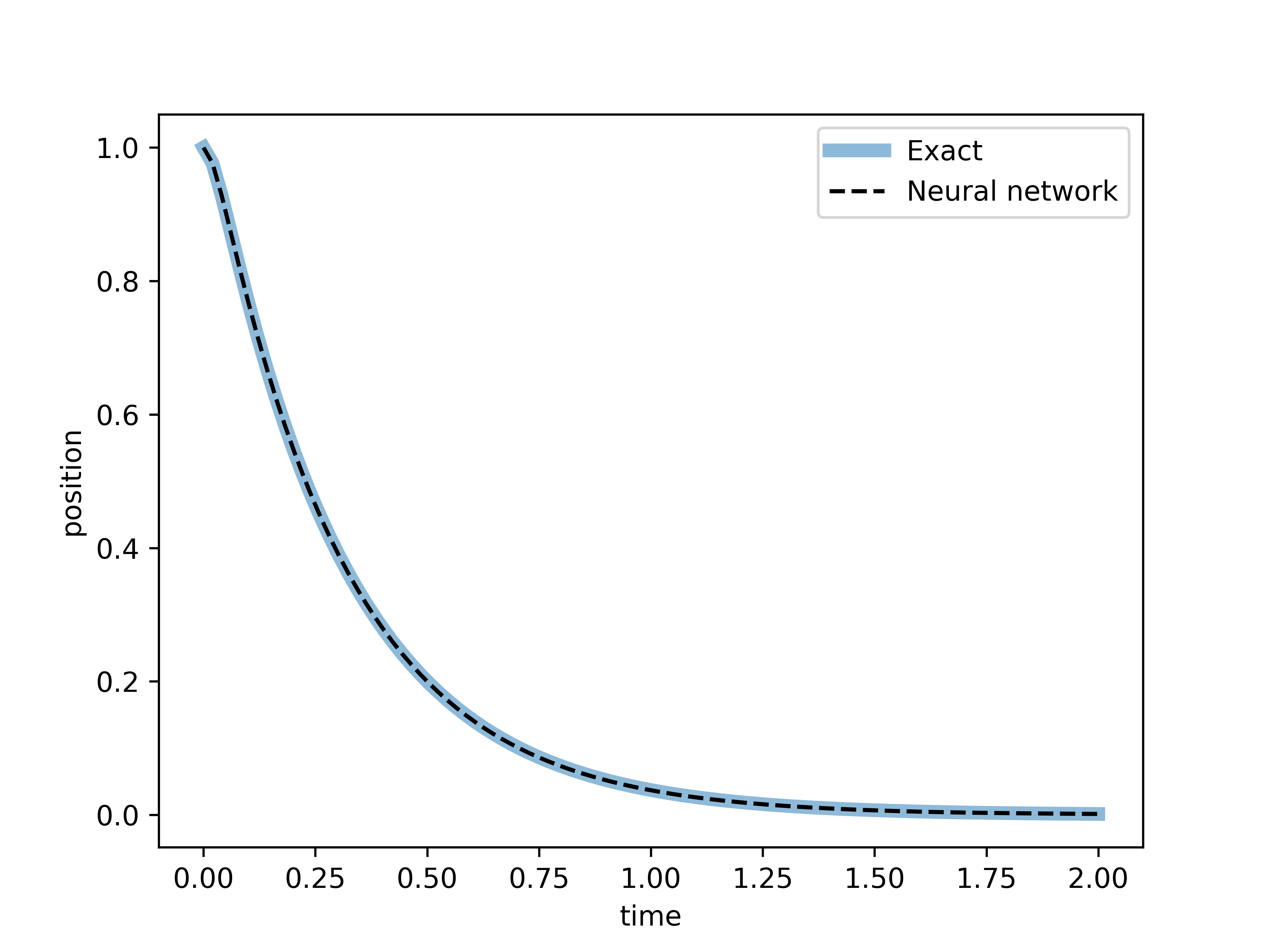
Now, as done in the previous case, let us compare to the exact solution found here to be given as:
where , , and . Note that the quantity under the square root in is the negative of the equivalent quantity found for the underdamped case, and it is always positive in the overdamped case .
w_over = torch.sqrt(torch.tensor(xi_over**2/4 - w0_over**2))
c1,c2 = (1+xi_over/(2*w_over))/2, (1-xi_over/(2*w_over))/2
x_sol_over = lambda t: x0*torch.exp(-.5*xi_over*t)*(c1*torch.exp(w_over*t)+c2*torch.exp(-w_over*t))
tt = torch.linspace(0, 2, 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N_over).numpy() #Neural
xt = x_sol_over(tt) #Analitic
fig, ax = plt.subplots(dpi=100)
ax.plot(tt, xt, label='Exact', linewidth=5,alpha=.5)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
Some comments on the results
While this is meant as an example of solving differential equations with neural networks rather then comments on the physics, It is a good closure to discuss the meaning of our results. We have separated our solutions in 3 schemes: underdamped, critically damped and overdamped. Let us plot the solutions found in each case.
tt = torch.linspace(0, 2., 100).unsqueeze(1)
with torch.no_grad():
xx_under = x_t(torch.Tensor(tt),N).numpy()
xx_crit = x_t(torch.Tensor(tt),N_critical).numpy()
xx_over = x_t(torch.Tensor(tt),N_over).numpy()
fig, ax = plt.subplots(figsize=(6,4))
ax.plot(tt, xx_under, '--', label='Underdamped')
ax.plot(tt, xx_crit, '--', label='Critical')
ax.plot(tt, xx_over, '--', label='Overdamped')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
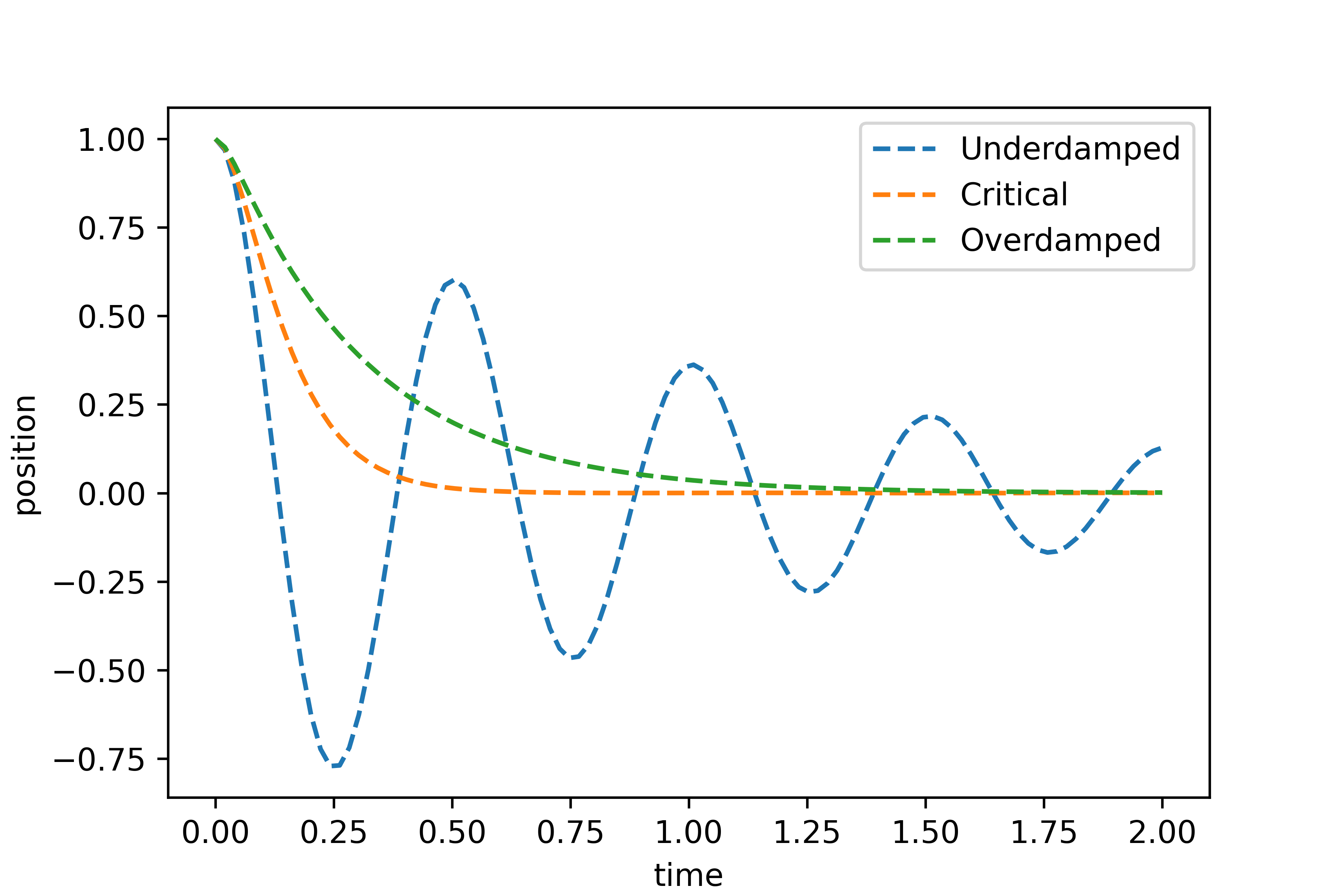
In the underdamped case, the system exhibits oscillations with gradually decreasing amplitude. This occurs when the damping is insufficient to prevent oscillations, but still present enough to reduce the amplitude over time.
In the critically damped case, the system returns to equilibrium as quickly as possible without oscillating. This represents a unique balance where the damping is just enough to prevent oscillations and allows the system to settle into equilibrium in the shortest time.
In the overdamped case, the system also does not oscillate but returns to equilibrium more slowly than in the critically damped case. The damping is so strong that it significantly slows down the system’s response.
When the neural network does not work
Notice that when solving the differential equation, we only evaluated the loss function within the interval . In other words, when training the network, we only enforced that the neural network solves the differential equation rithin that interval. We have no guarantee that the function given by the neural network will obey the differential equation outside of that interval. In fact, let us directly observe what happens when we try to plot the neural network solution for the underdamped case in the interval .
tt = torch.linspace(0, 3., 100).unsqueeze(1)
with torch.no_grad():
xx = x_t(torch.Tensor(tt),N).numpy()
xt = x_sol_under(tt)
fig, ax = plt.subplots(dpi=100)
ax.plot(tt, xt, label='Exact', linewidth=5,alpha=.5)
ax.plot(tt, xx, '--', label='Neural network',color='k')
ax.set_xlabel('time')
ax.set_ylabel('position')
plt.legend()
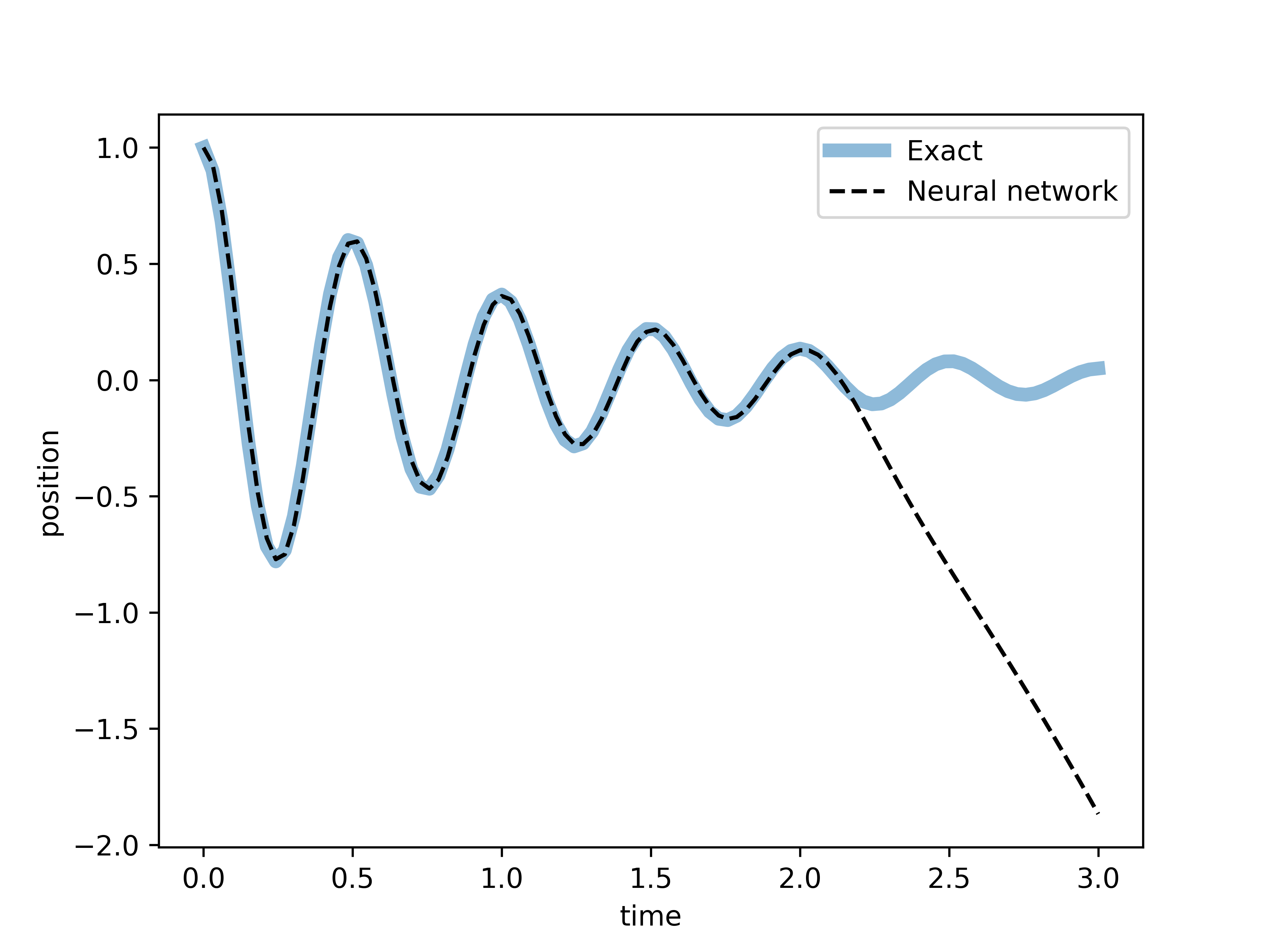
Thus, we finish this post by warning that using a neural network outside of its training interval can lead to unpredictable and unreliable results. The network may produce outputs that do not conform to the expected behavior of the system it was trained to model. This is because the neural network has not learned the patterns or relationships in the data outside the training interval, and it may extrapolate in ways that are not physically or mathematically accurate.
Nevertheless, the approach to solve differential equations presented here does not make any assumptions on the equation form. By incorporating a loss function that directly checks if the differential equation is solved, one can handle complex and diverse differential equations with minimal assumptions. This flexibility allows them to address a wide range of problems across various scientific and engineering fields, making them a powerful tool for virtually any context.
