
In recent years, there has been a marked increase in media and academic attention towards advancements in artificial intelligence, particularly concerning deep neural networks. The most pronounced surge in attention was observed following the release of ChatGPT last November. Although the usage of these tools is rooted in controversies (e.g. 1, 2, 3 ), it led to a similar spike in the interest for computational resources that facilitate the implementation of neural networks, such as the Python libraries PyTorch and TensorFlow. Nonetheless, I posit that the interest in neural networks may overshadow what I consider the pinnacle achievement of these libraries: the automatic differentiation technique known as autograd.
In what follows, I will give a brief example of using autograd with an explanation of what it does in calculus terms and use autograd to implement one of the most useful optimization methods (methods to find the maximum or minumim of a function) the gradient descent algorithm in no more than 5 lines of code.
Automatically calculating a gradient
First, let us study an example of a multivariate function. For notational simplicity let be a three dimensional vector and define the function
which we shall write in Python as
import torch
def function(a):
x,y,z = a
return x**2 + 2*y**2 + 3*z**2 - 2*x*y + 2*x*z -4*y*z +2*x -2*y +2
We can define the gradient of such function as
In broad terms, the gradient of a function is a vector that points in the direction of the steepest ascent of such function, meaning it points towards the direction, from , where the function would increase the most for a infinitesimally small jump. Conversely, moving against the gradient would take you in the direction of the steepest descent, or where the function decreases the most rapidly.
For our function defined above, the gradient can be calculated through the usual methods of calculus as
and implemented in Python (PyTorch) as
def gradient(a):
x,y,z = a
df_dx = 2*x - 2*y + 2*z + 2
df_dy = 4*y - 2*x - 4*z - 2
df_dz = 6*z + 2*x - 4*y
return torch.tensor((df_dx, df_dy, df_dz))
Let us see it working on a simple example, by calculating the gradient at the coordinate origin
a = torch.zeros(3,requires_grad=True)
gradient(a)
tensor([ 2., -2., 0.])
For more intricate functions, or when dealing with a high number of variables, manually computing each derivative and crafting a Python function to determine the gradient can become extremely laborious. In such scenarios, an automated tool like autograd proves to be considerably more convenient. To illustrate, using the previously defined function, we can demonstrate as follows:
1 – First we calculate the function at the point we ought to take the gradient
a = torch.zeros(3,requires_grad=True)
y = function(a)
To implement autograd, it is fundamental that the original variable were created with requires_grad=True.
2 – Then, we perform what is know as backward pass, in PyTorch that means using the bacward method
y.backward()
3 – From this, the gradient is directly calculated using the grad method into the original variable
a.grad
tensor([ 2., -2., 0.])
matching the directly calculated result. For a good understanding of what happens “under the hood’’ I refer to this lecture by Andrej Karpathy.
Before moving to an explanation of how to use autograd for finding minima, let us see how the two methods give rise to the same gradients for random values of :
for i in range(6):
a = torch.rand(3,requires_grad=True)
y = function(a)
y.backward()
print('autograd: {} \ndirectly calculated: {} \n'.format(a.grad,gradient(a)))
autograd: tensor([ 2.2223, -1.7236, 0.9384])
directly calculated: tensor([ 2.2223, -1.7236, 0.9384])
autograd: tensor([ 2.7886, -1.8427, 0.4914])
directly calculated: tensor([ 2.7886, -1.8427, 0.4914])
autograd: tensor([ 4.4235, -5.5024, 4.6813])
directly calculated: tensor([ 4.4235, -5.5024, 4.6813])
autograd: tensor([ 1.5094, 0.0904, -2.0093])
directly calculated: tensor([ 1.5094, 0.0904, -2.0093])
autograd: tensor([ 3.4180, -2.9908, 1.5999])
directly calculated: tensor([ 3.4180, -2.9908, 1.5999])
autograd: tensor([ 3.4566, -3.7455, 3.7018])
directly calculated: tensor([ 3.4566, -3.7455, 3.7018])
The gradient descent method
As previously mentioned, the gradient indicates the direction of steepest ascent and opositive to the steepest descent. Intuitively, we can envision a method to find the minimum of a function by:
- evaluating the gradient.
- taking a small step in the negative gradient direction.
This process is repeated until we find a point where all components of the gradient are zero. Because you are consistently moving towards the steepest descent, this would indicate a point of minima. In mathematical terms, we can express a move from a point to as
where is the relative step size which, in the deep learning community, is also referred to as the learning rate. If is not a minima or a maximum, it is mathematically guaranteed that there exists a sufficiently small positive value of that implies
To demonstrate this in practice, let us find the minimum of the function described earlier. Using standard calculus, we determine that there is a minimum as with . Let us try to find that using gradient descent, such a task is straighforward in PyTorch, let us fist decide on an initial point and a learning rate as
a=torch.zeros(3,requires_grad=True)
learning_rate =.01
Now, let us use it by finding the final state after 1000 interactions of the algorithm, this is easily done in PyTorch as
for i in range(1000):
y = function(a).backward()
with torch.no_grad():
a += -learning_rate * a.grad # Update x in the direction of the gradient
a.grad.zero_()
The final value of from this loop is
a
tensor([-1.0006, 0.9993, 0.9997], requires_grad=True)
which is close to the known maxima , but it doesn’t match with full mathematical precision. This indicates that a mere 1000 steps was not sufficient to pinpoint the minima with the accuracy inherent to floating-point precision.
This observation shows the need for a mathematical criterion to determine an appropriate stopping point. Given that a minima implies that all components of the gradient converge to zero, a practical approach would be to continue iterations until the absolute values of all gradient components fall below a specified “tolerance” value. This can be implemented as follows:
tol = 1e-5 #tolerance value
a=torch.zeros(3,requires_grad=True) #reseting initial
stop = False
while not stop:
y = function(a).backward()
stop = torch.max(torch.abs(a.grad))<tol
with torch.no_grad():
a += -learning_rate * a.grad # Update a in the direction of the gradient
a.grad.zero_()
Thus leading to the correct value
a
tensor([-1.0000, 1.0000, 1.0000], requires_grad=True)
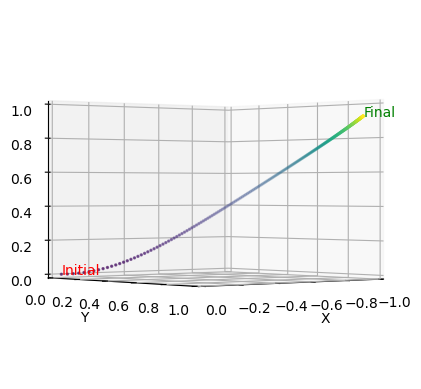
To encapsulate the trajectory pursued by gradient descent, the subsequent graph maps its path in a 3D space. This visualization brings to light the intricate journey a model undertakes to reach its optimal state. Beginning with an initial guess, every ensuing step—marked distinctly by a point—depicts the model’s progressive descent towards the function’s minima. In the graph, the color of these points transforms from purple, indicative of the initial steps, to yellow as the descent progresses.
tol = 1e-5 #tolerance value
a=torch.zeros(3,requires_grad=True) #reseting initial
a_all =[]
for i in range(250):
y = function(a).backward()
with torch.no_grad():
a += -learning_rate * a.grad # Update a in the direction of the gradient
a.grad.zero_()
a_all.append(a*1)
a_all = torch.stack(a_all).detach().numpy()
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.scatter3D(a_all[:,0], a_all[:,1], a_all[:,2], c=range(len(a_all)),s=2)
ax.text(*a_all[0], "Initial", color='red')
ax.text(*a_all[-1], "Final", color='green')
ax.view_init(0, 50)
ax.set_xlabel('X'), ax.set_ylabel('Y'), ax.set_zlabel('Z')
ax.set_xlim((-1,0)), ax.set_ylim((0,1)), ax.set_zlim((0,1))
plt.show()
Conclusion
Autograd is a fundamental feature in PyTorch, equipping the framework with the capability to automatically compute derivatives for a myriad of operations, including those that span multiple layers and functions. By eliminating the complexities of manual differentiation for developers, Autograd simplifies the implementation of gradient descent. At its core, it’s this very principle of gradient descent that drives the training of neural networks. The discussion presented here centered on how gradient descent finds the minima of a function. Typically, however, PyTorch users lean on the optim package that gradient descent and other optimization algorithms already implemented, however a survey of those will be left for a future blog post.
