
Introduction
It is undeniable that there has been an explosive interest in data analysis and machine learning tools worldwide over the past decade. The availability of vast amounts of data, coupled with advancements in computing power and technology, has propelled data science to the forefront of various academic and industrial endeavors. Additionally, the widespread adoption of user-friendly tools, interactive dashboards, and intuitive visualizations, individuals with varying levels of technical expertise can now engage in data exploration and analysis.
While these tools have certainly made data-driven solutions more accessible, it is vital to recognize the potential these user-friendly tools have to cloud the user’s view of what’s really going on, meaning by hiding the statistical labor under the hood. Beyond telling convincing stories by presenting data in simple, attractive formats, actually understanding probability theory can help users avoid the false certainty that comes from overlooking the inherent uncertainty probabilistic analysis entails.
As the most rigorous approach to handling data, this is precisely where Bayesian statistics excels In contrast to classical (or frequentist) statistics, which treats probabilities as long-run frequencies, Bayesian statistics regards probabilities as measures of rational belief, thus enabling a deeper, more nuanced, and accurate understanding of the underlying phenomena.
Moreover, Bayesian statistics offers a natural framework for managing uncertainty and quantifying our confidence in the results. Instead of providing singular point estimates, Bayesian methods generate probability distributions that encompass the entire spectrum of possibilitiess, along with their associated likelihoods. This overarching perspective on uncertainty not only aids in making informed decisions but also facilitates effective communication of results, emphasizing the vital role of probabilistic thinking in today’s data-driven world.
A short primer on Bayesian statistics
Bayes’ theorem is a fundamental result in probability theory that establishes a relationship between conditional probabilities. It provides a way to update our beliefs about the occurrence of an event based on new evidence or information. The theorem is stated as follows:
where:
- is the conditional probability of event A given event B.
- is the conditional probability of event B given event A.
- is the probability of event A.
- is the probability of event B.
In essence, Bayes’ theorem allows us to calculate the probability of A given B by multiplying the probability of B given A with the prior probability of A, and then dividing it by the probability of B.
We can see how this relates to modeling data, by framing A as a Model and B as a set of Data, and rewriting Bayes’ theorem accordingly
Where
- is the likelihood, meaning the probability that the data were observed given the model.
- is the prior probability, or the initial belief on the model before considering any new data, the good practice is to choose the prior in a way that is as uninformative as possible.
- , often refered to as evidence, is a normalization factor which is, in principle, indepent of the model (examples in the following section).
- Finally, represents the posterior probability, this name is chosen because if we understand Bayesian analysis as rationally updating our beliefs based on the data, it encodes our beliefs after taking the data into account.
The posterior becomes, then, the main object of interest as it combines, with the necessary mathematical rigor, the previous beliefs, represented by the prior, with the the rational change of belief, captured by the likelihood. Let us proceed with a concrete example.
Example – The (allegedly) biased coin
As a first example, let’s consider a coin and try to determine whether it is biased or not. The main parameter we are interested in, denoted as qq, represents the probability of the coin landing on “heads” in a single toss. To estimate the value of , we will analyze the results (number of “heads”) obtained from a series of coin tosses.
The synthetic experiment
For an unbiased coin, we expect . However, unlike most experiments in biophysics (the main research interest here at Pressé lab), this one can be easily performed by the reader at home. Nevertheless, to save them from tedious labor and to illustrate the results in this post, let’s create some Python code that simulates this experiment for a coin with a whose “heads” probability is denoted as (which we shall refer to as the ground truth).
In this code block we fixed the seed for reproducibility, this means that the Python code utilizes a fixed seed value for the random number generator before performing the coin toss simulations. If the seed remains the same, subsequent random number generation, will be consistent each time you run the code. For details see this.
import numpy as np
from matplotlib import pyplot as plt
np.random.seed(42)
def experiment(q_GT,N):
return np.random.rand(N)< q_GT #True means heads.
Having this function, let us ‘flip’ this virtual coin for tosses with = 0.6, and show the results of the first tosses
q_GT = .6
data = experiment(q_GT,1000)
data[:10]
array([ True, False, False, True, True, True, True, False, False,
False])
The variable data is a boolean array where each element corresponds to an independent coin toss. Above we have shown the results of the first tosses, and the True boolean value corresponds to a “heads” result. The number of heads in the first tosses and the total number of heads can be obtained, repectively, as
data[:10].sum(), data.sum()
(5, 613)
since summing a boolean array in numpy gives the number of True elements.
One “instinctive” answer would be to give, after tosses, the value thus incorrectly claiming that the biased coin is fair. After tosses, however, we would instead give the value which is closer to the ground truth value,
Learning the heads probability through Bayes
However, to what extent can we claim to observe the coin’s bias from the data? How many coin tosses would be necessary to assert with certainty whether the coin is unbiased? To answer these questions, we will adopt the Bayesian approach to analyze the data obtained from the coin tosses and estimate the probability parameter with appropriately calculated uncertainty.
Prior Distribution:
Here, we use the uniform distribution over the interval [0, 1] as the prior.
This is often preferred to avoid biasing our results, indicating that we have no strong prior knowledge about the value of . However, in other Bayesian inference scenarios, one may possess prior knowledge about the parameters of interest. In such cases, it is entirely acceptable to incorporate informative priors that align with one’s understanding of the problem.
Additionally, it is common to select conjugate priors for the sake of mathematical simplicity. As the sample size grows, the influence of the prior diminishes, and the posterior distribution is primarily shaped by the likelihood function.
Likelihood:
If the probability of obtaining heads is and, consequentially, the probability of obtaining tails is , the likelihood of a single datum is given as
So a dataset to of independent tosses will have it’s likelihood given by
Given the data structure previously mentioned, a Python function that calculates the likelihood is given by
def likelihood(data,q):
return q**(data.sum())* (1-q)**((1-data).sum()) #the sum method treats the boolean `True' as 1 and `False' as 0.
Posterior Distribution:
The posterior distribution, denoted as , is proportional to the product of the prior and the likelihood:
Note that the evidence depends on the data but not on . Since the data won’t change, it is merely a constant value that can be calculated by imposing that a probability distribution sums to one
Leading to
Next, we will introduce a Python function that computes the posterior for an array of values between 0 and 1. Although the integral in the denominator can indeed be can be calculated analitically we’ll compute it numerically in this context to avoid diving into detailed discussions not intended for this blog post.
def posterior(data,precision=.001):
q = np.arange(0,1+precision,precision)
dq = q[1]-q[0]
#non-marginalized posterior, we comment the prior calculation as we are using a uniform one.
nm_posterior = likelihood(data,q) #*prior(q)
#denominator integral for marginalization
integral = np.sum(nm_posterior)*dq
posterior = nm_posterior/integral
return q, posterior
Now in order to see how the posterior evolves with the amount of data gathered, let us plot the posterior for 10,100 and 1000 datapoints.
for j in [10,100,1000]:
plt.plot(*posterior(data[:j]),label='{} datapoints'.format(j))
plt.axvline(q_GT,color = 'y',label='Ground truth')
plt.xlabel(r'$q$')
plt.ylabel('Posterior')
plt.legend()
<matplotlib.legend.Legend at 0x7fd8483d92e0>
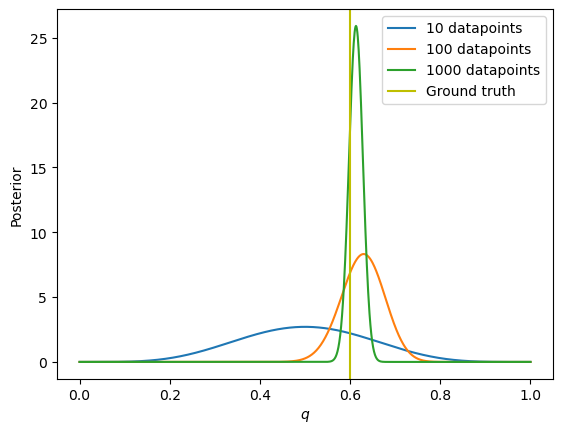
Implying that, as expected, a larger number of samples makes the posterior distribution becomes tighter around the real value (ground truth).
It’s important to note that the Bayesian approach considers uncertainty rigorously and allows us to quantify it through probability distributions. As we collect more data (perform more coin tosses), our uncertainty about the true value of reduces, our uncertainty concerning the actual value of diminishes, yielding a more accurate estimation.
As one might imagine, it is common in science that it is not feasible to obtain an arbitrarily big amount of data. However, it is still possible to obtain a rigorous estimation of the ground truth through the concept of credible intervals, which we will dive into now
Credible intervals
If we focus on the posterior results previously commented, let us say that I ought to say something like: “There is a probability that lies within the interval to “. In more mathematical rigor we must say and adapted for the problem at hand, we must find an interval such that
where is your desired credibility ( in the sentence above).
Naturally, the credible interval is not uniquely defined and there are many different ways to create one. For our propose here, we shall find the smallest interval centered at the maximum of the posterior (sometimes refered to as the posterior mode) calculated up to a precision of . This is done by the following function
def credible_interval(data,conf=.95):
q,post = posterior(data,precision=.001)
dq = q[1]-q[0]
max_ind = post.argmax()
dif = 1 #spacing around the maximum posterior
while np.sum(post[max_ind-dif:max_ind+dif])*dq<conf:
dif+=1
return q[max_ind-dif],q[max_ind+dif]
The example below means that
credible_interval(data,conf=.95),credible_interval(data,conf=.5)
((0.582, 0.644), (0.602, 0.624))
the credible interval given all of our coin tosses is and the credible interval given all of our coin tosses is . Or alternatively, after these tosses, we are lead to the conclusion that there is a probability that the real probability that the coin to land on `HEADS’ is between and .
Before concluding the blog post, let us visualize how the credible interval evolves with the number of datapoints
fig,ax =plt.subplots(3,1)
label = True
for (axi,lim) in zip(ax,[10,100,1000]):
q,post =posterior(data[:lim])
axi.plot(q,post,label='Posterior')
axi.axvline(q_GT,color = 'y',label='Ground truth')
conf50,conf95 = credible_interval(data[:lim],conf=.5),credible_interval(data[:lim],conf=.95)
axi.fill_between(conf50,(0,0),(post.max(),post.max()),color='r',alpha=.5,label='50% credibility')
axi.fill_between((conf95[0],conf50[0]),(0,0),(post.max(),post.max()),color='r',alpha=.25,label='95% credibility')
axi.fill_between((conf95[1],conf50[1]),(0,0),(post.max(),post.max()),color='r',alpha=.25)
if label:
fig.legend(loc=8,ncol=4,bbox_to_anchor=(.55,1.001))
label=False
axi.set_ylabel('{} datapoints'.format(lim))
ax[-1].set_xlabel(r'$q$')
fig.tight_layout()
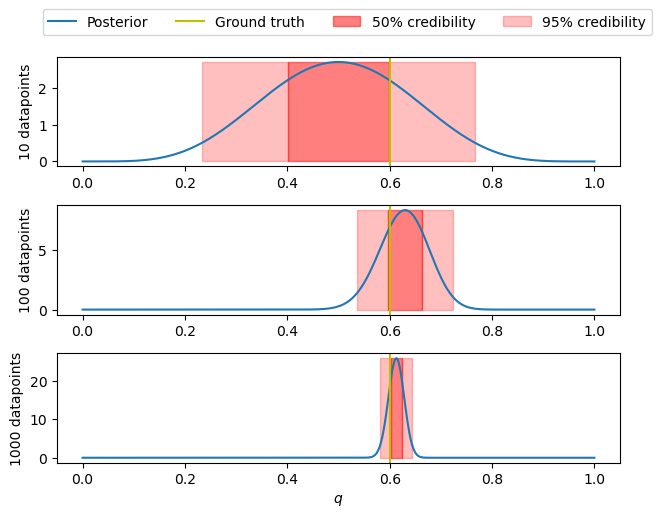
Coherently with what was previously discussed, a larger number of samples makes the credible interval tighter around the real value (ground truth).
fig,ax =plt.subplots(1,figsize=(8,4))
ax.axvline(q_GT,color = 'y',label='Ground truth')
label =True
for lim in [10,32,100,316,1000]:
q,post =posterior(data[:lim])
#axi.plot(q,post,label='Posterior')
#axi.axvline(q_GT,color = 'y',label='Ground truth')
conf50,conf95 = credible_interval(data[:lim],conf=.5),credible_interval(data[:lim],conf=.95)
ax.plot(conf95,lim*np.ones(2),lw=4,color='r',alpha=.5,label='95% credibility')
ax.plot(conf50,lim*np.ones(2),lw=8,color='r',alpha=1,label='50% credibility')
if label:
fig.legend(loc=8,ncol=4,bbox_to_anchor=(.55,1.001))
label=False
ax.set_xlim(0,1)
ax.set_yscale('log')
ax.set_ylabel('# of datapoints',fontsize=20)
ax.set_xlabel(r'$q$')
fig.tight_layout()
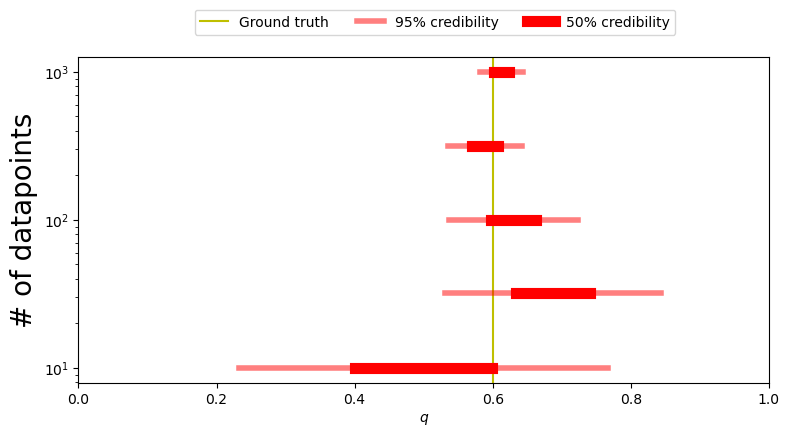
Mean and standard deviation
It is fascinating to observe the diverse array of topics that the discussion covered here. The discourse not only delved into probability theory but also encompassed areas like modeling, calculus, and numerical analysis.
However, it is possible that many readers approached the problem from a different angle, suggesting that the value of must fall between and where, in this case, is the average (fraction of heads) and is defined as
with takes the value 1 if the -th toss was “heads” or 0 if the -th toss was “Tails” and being the data complete standard deviation.
Although you may have encounted this method before (If any of the readers had me as their instructor of physics lab I they may remember that we did this exact example with real coin tosses). Interestingly, when we assert that the value lies between and , we are essentially employing the principles of Bayesian inference, even though the rationale behind it is often left unexplained. To be more specific without diving into much detail, the interval approximates the credible interval obtained through rigorous inference, but only for large number of data points . The block of code below shows how this convergence happens
for lim in [10,25,50,100]:
print(lim,' datapoints:')
mu = data[:lim].mean()
sig = data[:lim].std()/np.sqrt(lim)
print('mean and std ', np.round((mu + np.array((-1,1))*sig),3))
print('68.3 % credibility', np.round(credible_interval(data[:lim],.683),3))
10 datapoints:
mean and std [0.342 0.658]
68.3 % credibility [0.355 0.645]
25 datapoints:
mean and std [0.587 0.773]
68.3 % credibility [0.589 0.771]
50 datapoints:
mean and std [0.614 0.746]
68.3 % credibility [0.615 0.745]
100 datapoints:
mean and std [0.582 0.678]
68.3 % credibility [0.582 0.678]
This is a direct consequence of the central limit theorem. However, it does not replace careful Bayesian inference for several reasons, some easier to see than others.
The most evident of these reasons, as it can be seen above, emerges when dealing with a limited number of data points. In such instances, relying solely on the calculation of mean and standard deviation can yield misleading and erroneous outcomes. In fields where experiments are labor-intensive or expensive, the luxury of augmenting the dataset at will is not always viable. Moreover, some fields are grounded in observational data (e.g., astronomy, sociology, economics) and, by consequence, there is a limitation on the amount of data available given by the system under study. In such cases, delving into the intricate study of probabilities inherent to Bayesian inference offers the most honest comprehension of the information concealed within the data.
Less obvious ones include:
- When the posterior is multimodal, meaning it has multiple distinct peaks (modes), the process of Bayesian inference gives answers with the adequate amount of nuance and complexity while methods that rely on single-point estimates, or the mean/mode of the posterior distribution, do not accurately capture the underlying uncertainty present in the data.
- Certain systems have a data acquisition form where the sampled values that intrinsically deviates from the mean. As happens with distributions that violate the conditions of the central limit theorem. In the near-future I will post again in this same website a clear example when that happens. In such we will observe how these naive methods fail but rigorous Bayesian inference succeeds.
Conclusion
This blog post has given us an overview of Bayesian inference with a concrete example: finding the probability that a coin lands on heads. We constructed the Bayesian formalism by defining the prior, studying the system to obtain likelihoods, and calculate the posterior. This blog post also introduces the important (albeit not always taught in basic tutorials such as this) concept of credible interval. This was followed by a brief discussion on the use of more naive methods of statistical inference.
In a future blog post we will dive into an example where these naive methods fail thus highlighting the need of an inference procedure that takes the rigorous aspect of probability to the core.
