
Introduction
The lighthouse problem serves as a deceptively simple but captivating challenge in the field of statistics. As we shall explore, it subverts our conventional understandings of data and probability. Owing to its intriguing nature, this problem, introduced by Gull, is often featured in textbooks on Bayesian statistics, such as the one by Sivia. The problem is usually presented as
Imagine a faulty lighthouse situated at an unknown coastal location, denoted by , and at a height above sea level. While the lighthouse emits flashes at random angles, you can only observe the points where the light strikes the coast, without directly seeing the lighthouse itself. Given a series of such observations, how can you determine the lighthouse’s location?
First, let’s clarify the geometry of the situation. We introduce the angle, denoted as , between the lighthouse and the lightbeam, and the position where the lightbeam makes contact with the shore, referred to as . All the relevant variables are depicted in the figure below.
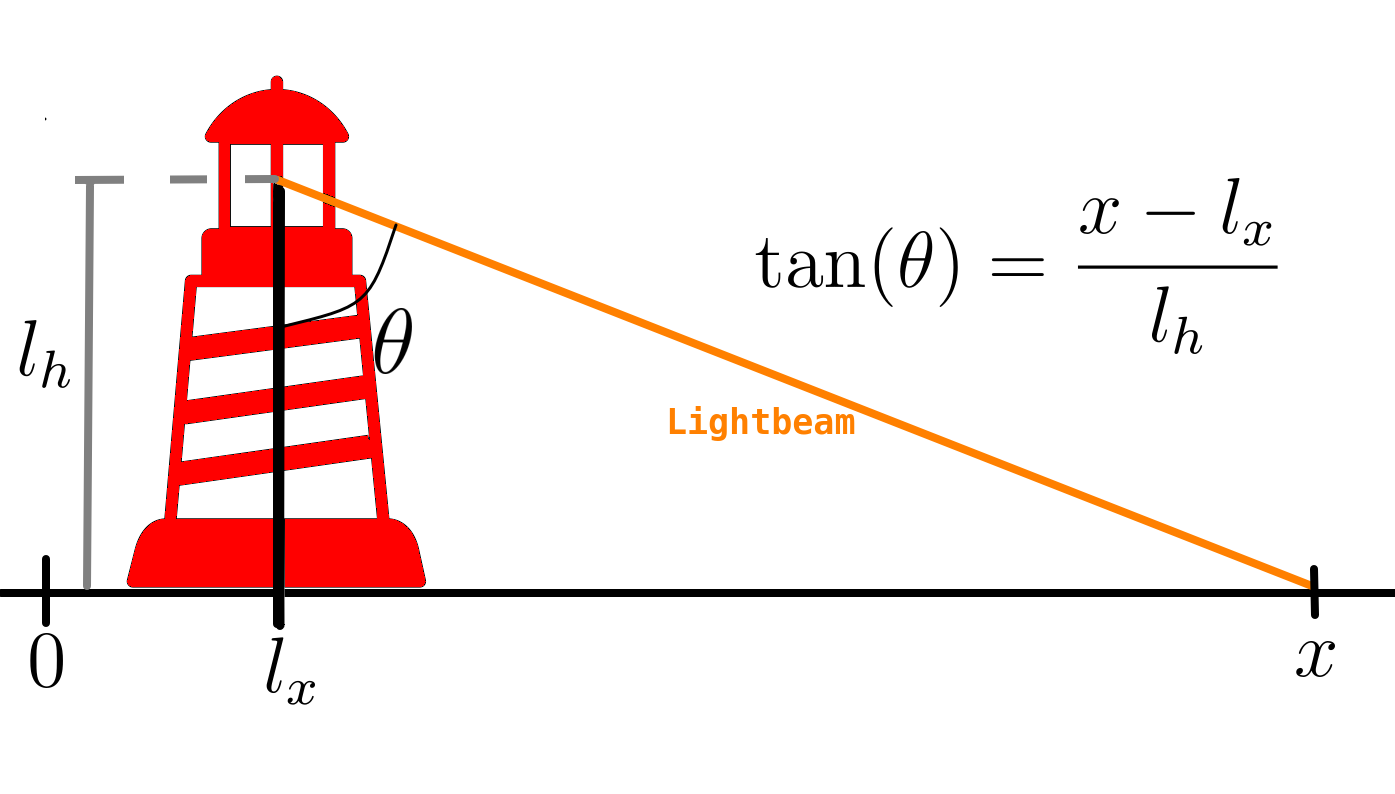
The goal is, then, to use observations of to infer (or learn) the values of and . In simpler terms, can we determine the location of the lighthouse by observing where the lightbeam is seen on the shore? For the present blog post we will assume that the height is already known, this is because for now we want to avoid the difficulties related to learn multiple parameters, but I will show how it is possible to learn and together in a following blog post (stay tuned).
While this blog post can be read independently, it builds upon the Bayesian language introduced in my previous blog post.
To explain how we can infer from , let’s first delve into how synthetic data following this model would be generated. We will then use data visualization to gain insights regarding . During this exploration, we will discover that the naive method, which involves calculating the mean and standard deviation, falls short. With this understanding, we will construct a Bayesian model and observe that it indeed leads to accurate inference on the lighthouse’s position. This example highlights the necessity of data science approaches grounded in a rigorous understanding of probabilities.
Generating (synthetic) data
First, let us decode what the question encodes with “the lighthouse emits flashes at random angles”, this means that is uniformly distributed acute angle, that is for . An obtuse angle would mean that the lightbeam does not hit the coastline. By looking back at the figure above trigonometry lead us to obtaing the lightbeam hit position in terms of the angle as
First, let us simulate the results of such experiment or, in other words, generate synthetic data. Here, for the sake of the argument let us assume that the lighthouse is located at the position origin, and has unit height . Generate synthetic data consists of sampling the random and calculating through the formula above. The complete code, as well as this post in ipython notebook format is available in my GitHub
import numpy as np
from matplotlib import pyplot as plt
np.random.seed(42)
l_x,l_h = 0,1 #setting ground truth
th = np.pi*(np.random.rand(100000)-1/2) #sample theta
x = l_x +l_h*np.tan(th)
Before moving on with inference, let us try to visualize the data directly. One straightforward idea would be to simply create the histogram of the data. However a first attempt using the usual tools yields an awkward result.
#Removed data block, see notebook on GitHub for full code
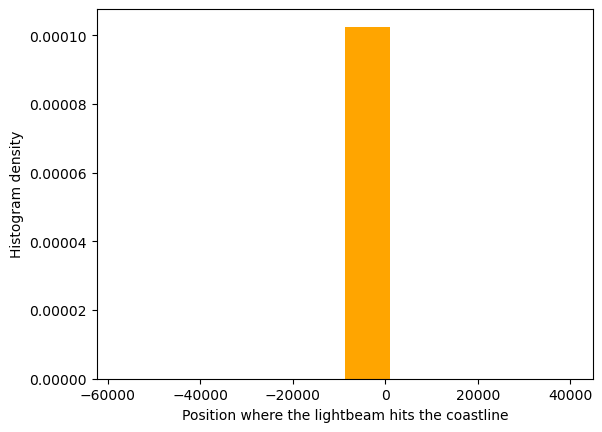
The reason for this rather uninformative result comes from the fact that the dataset includes some rare but extremely large values. Let us observe this by visualizing the data in two different formats: firstly let us recreate the histogram but only for values within some region (chosen arbitrarily as [-50,50]), which will create a more reasonable histogram; and second, lets create a data scattered plot so that we can directly observe the rare deviant datapoints.
#Removed data block, see notebook on GitHub for full code
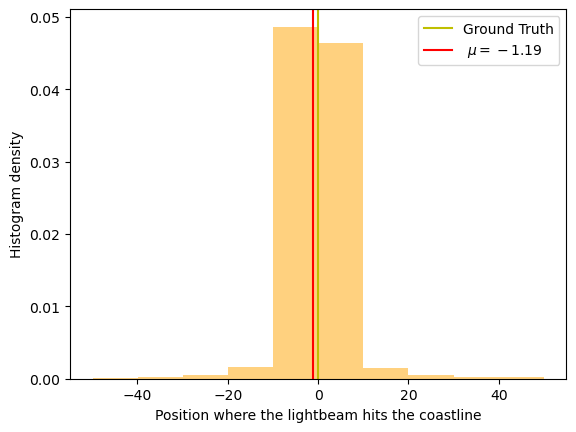
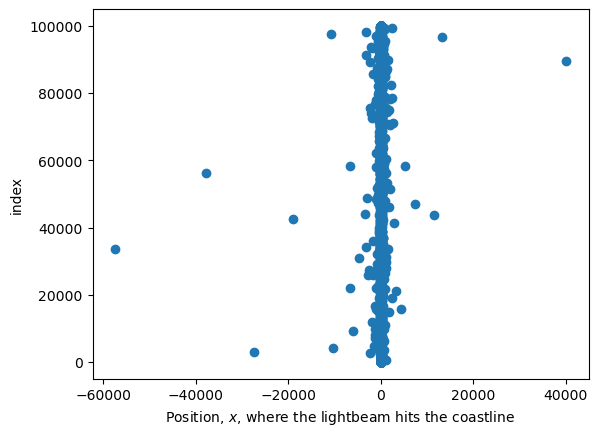
As these plots were generated with synthetic data, it’s important to emphasize that the rare instances of values that significantly deviate from the mean should not be considered as ‘outliers’ in the traditional sense, nor should they be attributed to modeling innacuracy or experimental error. Instead, these extreme values are a direct outcome of the inherent characteristics of the problem being studied. If we go back to Eq (1) we see that will get arbitrarely large as approaches .
Now, considering the difficulties regarding data visualization alone, one may think that using the data visualized above to infer the lighthouse’s position will be a challenging task. In order to show this, we will use the opposite strategy from my previous blog post. Here we begin by using the naive ‘‘mean and standard deviation’’ route, which will produce unsound results. Later, I will show how an approach based on correctly calculating the likelihood and, by extension, the Bayesian posterior lead to appropriate results.
Mean and standard deviation
As one looks into the lighthouse image, they may think that the mean value of should correspond to the position of the lighthouse, if enough data points are drawn. If someone with more mathematical familiarity looks into Eq. (1), they might see that the probability of is symmetric around — meaning the probability for is equal to the probability of . Therefore it must follow that that the should be symmetric around — the probability of should be equal to the probability of for any .
Now confident in the convergence of the mean to , one could further argue that the actual value of should fall within the interval , where represents the mean (or average) of , and denotes the standard deviation of divided by the square root of the number of data points see discussion in the previous post.
One can observe, however, what happens when we try to visualize this interval (the complete code,as well as this post in ipython notebook format is available in my GitHub )
#Removed data block, see notebook on GitHub for full code
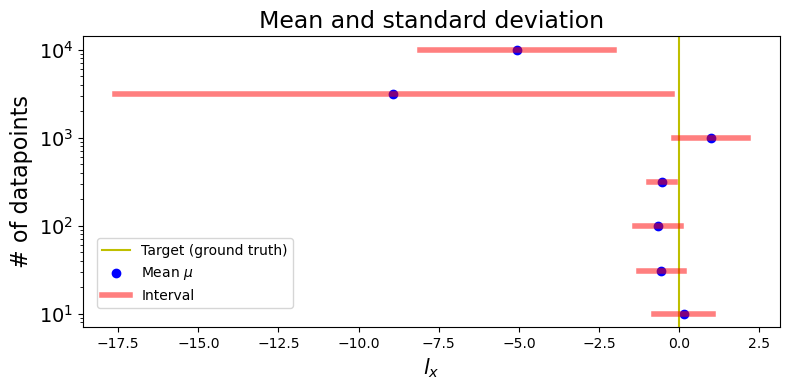
It becomes evident that, as the number of data points increase, the mean estimate of does not converge towards the ground truth value. Furthermore, the ‘‘confidence interval’’, determined by the mean and standard deviation, does not narrow as we increase the number of datapoints. This observation suggests that the mean and standard deviation alone are insufficient to infer the lighthouse’s position.
Bayesian
Having established, in pratical terms, that the somewhat naive approach of mean and standard deviation fails in finding the position of the lighthouse, let us actually study the problem based on the Bayesian paradigm.
Cauchy distribution
Following the Bayesian language as defined in the previous post, we ought obtain the likelihood of a data point . In the paragraph where Eq. (1) is introduced, we discuss the uniform probability distribution for the angle , and obtain in terms of , , and . We can transform the probabilities for into probabilities for as
Read this for more detail on how the equation above is derived.
Now, after differentiating Eq. (1) and performing some algebra, you obtain the conditional probability density for given and as
This expression represents the probability density of observing a particular value when you have knowledge of the parameters and . Later we will use Bayes theorem to obtain the probability of given the observations (and in a future blog post we wil obtain the probabilities of both and ).
The probability distribution in Eq. (3) is also known as the Cauchy distribution.
We observe that the probability of has a maximum at , and it is symmetric around . This observation adds an intriguing layer of complexity, as one might expect the mean of to converge to which, surprisingly, it does not.
In what follows, we procced into using Bayesian inference to address the lighthouse problem. However, it is worth noting that the perplexing behavior of the mean and standard deviation intervals can be attributed to certain unique properties of the Cauchy distribution. I will elaborate on these properties in a future blog post.
Likelihood
When we obtain data, in the form of a set of observations of the light, that are independent and identically distributed, meaning each data point is generate without correlation to the previous ones, and all are drawn from the same lighthouse position. As such, the likehood for this data is given by multiplying Eq. (3) for every data pont thus yielding
Above and for the remainder of this post, the explicit dependance in is ignored, as we assume its value is already known, in a future blog post we will study how the problem changes when one tries to infer both and .
Since each value within the product in Eq. (4) is small, and multiplying a large batch of small numbers can be approximated to zero by the computer, it’s a useful technique in inference to calculate the logarithm of the likelihood instead
This is calculated through the following block of code:
def log_like(x,lx,lh):
X,LX=np.meshgrid(x,lx)
den = (X-LX)**2+lh**2
return np.sum(np.log(lh)-np.log(np.pi)-np.log(den),axis=1)
The use of np.meshgrid and np.sum above are methods to avoid the overuse of for loops or, in other words, to vectorize the code.
Prior
Following the Bayesian framework outlined in the previous post, we aim to incorporate prior information into our inference process. In this context, we want to choose a prior that is as uniform as possible to avoid introducing bias into our Bayesian inference. A uniform prior essentially means that we have as little prior information or preference as possible, allowing the data to have the most significant influence on our final inference. This approach is often referred to as non-informative or uninformative prior, as it doesn’t favor any particular parameter value and lets the data speak for itself. Here we will assume a prior of the form
Or, in other words, the prior is uniform in the interval and take the limit .
Posterior
From the previous discussion, we obtain the posterior using the Bayes’ theorem:
with the evidence, , being a proportionality constant that does not depend on will be referred to as . By substituting Eqs. (5) and (6) and taking the logarithm above we obtain
thus leading to a posterior of the form
where , which does not depend on and is numerically calculated by ensuring that the posterior is a probability distribution, i.e., .
The following block of code gives a function to calculate the posterior with the appropriate normalization.
def posterior_x(data,precision=.001):
lx = np.linspace(-10,10,int(1/precision)+1)
dlx = lx[1]-lx[0]
#non-marginalized posterior
l = log_like(data,lx,l_h)
l -= l.max()
posterior = np.exp(l)
#Calculating Z' numerically
Zprime = np.sum(posterior)*dlx
#marginalized
posterior = posterior/Zprime
return lx, posterior
The posterior in Eq. (9) provides us with all the necessary tools for conducting Bayesian inference for the lighthouse problem. As an initial step to visualize the posterior, let’s juxtapose a graph of the posterior with a density histogram, both obtained using only the first 100 data points we generated.
#Removed data block, see notebook on GitHub for full code
The data mean is -0.6674364059676746, while the posterior maximum is -0.09999999999999964
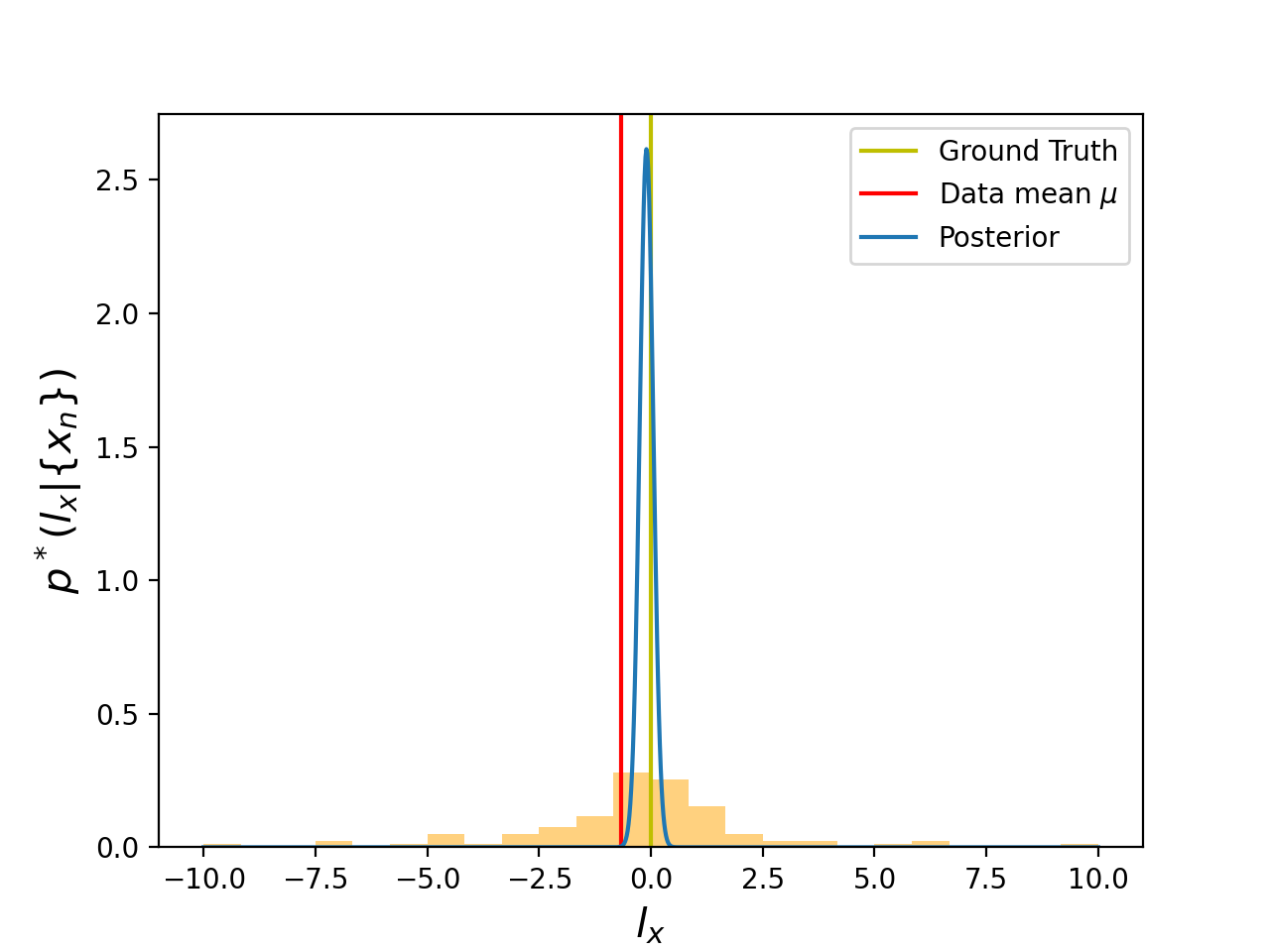
The figure above reveals two intriguing observations. Firstly, the posterior for exhibits a qualitatively distinct behavior compared to the histogram of , displaying a significantly narrower distribution. Secondly, and perhaps more importantly, the posterior’s maximum value is remarkably closer to the true ground value of when compared to the data mean . This serves as a compelling example of how a rigorous study of probabilities translates into more precise inferences regarding the lighthouse’s position, .
Credible intervals
Following the procedure outlined in the
previous blog post, we move into calculating the Bayesian credible interval from the posterior. As in the previous post we ought to find the smallest symmetric interval around the posterior maximum (or mode) such that the probability that is within that interval is larger than . The code for finding it is outlined below.
def credible_interval(data,conf=.95,precision=.001):
q,post = posterior_x(data,precision)
dq = q[1]-q[0]
max_ind = post.argmax() #find the index for the posterior maximum
dif = 1
while np.sum(post[max_ind-dif:max_ind+dif+1])*dq<conf: #increase the interval until finding the desired credible interval
dif+=1
if dif==1:
return credible_interval(data,conf=.95,precision=.001/4)
return q[max_ind-dif],q[max_ind+dif]
With this, we can graph the credible interval as a function of the number of datapoints, similarly to our previous plots of the mean and standard deviation intervals. For comparison, we plot the mean and standard deviation intervals once again. Our goal here is to see how the credible interval changes with the size of the dataset. We will obtain the interval generated by both methods with the same dataset of datapoints (the first generated), with varying from to .
While the block of code below is large, it is not more than code needed to make a graph in Python, the reader can go straight to the final result.
#Removed data block, see notebook on GitHub for full code
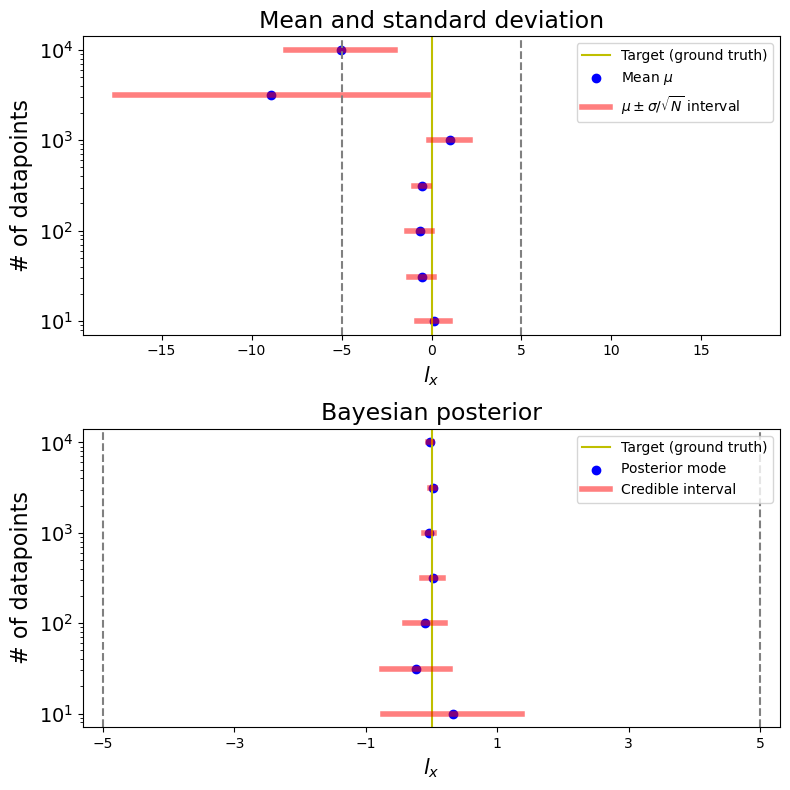
Here, we observe that the Bayesian credible interval is significantly more accurate than the one obtained naively through the mean and standard deviation. This holds true even for a small number of data points (note that the range in the bottom figure is significantly narrower when compared to the top one, the grey dashed line correspond to the same values in both graphs). The accuracy of using Bayesian becomes even more impresive when we notice that, while the mean and standard deviation interval should correspond to the 63.8% credible interval, the second graph presents the 95% credible intervals. This reinforces the importance of embracing a more comprehensive understanding of probability, as straightforward (yet somewhat naive) statistical methods can easily lead to misleading results.
Conclusion
Through the simple example of the lighthouse problem, this blog post has provided insights into the complexities of statistical analysis. It has underscored the limitations of relying solely on mean and standard deviation, particularly when confronted with distributions such as the Cauchy distribution that deviate from the central limit theorem. While we have briefly discussed some of the underlying reasons for this unconventional behavior, a more comprehensive examination of the Cauchy distribution will be the topic of a forthcoming blog post.
Furthermore, we have introduced the prospect of inferring both the lighthouse’s position, designated as , and its height, , based on lightbeam observations, . This converts a one-dimensional dataset (in which all values are single valued) into a two-dimensional posterior distribution, expressed as . A comprehensive tutorial for this more complex problem will be the topic of another future blog post.
I invite readers to remain engaged and follow for the forthcoming publications, where we will delve further into these nuanced aspects of probability and statistical analysis.
This post is available as a iPython notebook in my GitHub repository.

Comments
One response to “Why do we need Bayesian statistics? Part II — The lighthouse problem (tutorial)”
[…] the previous entry of this tutorial series, we studied the lighthouse problem. The goal was to infer (or learn) the position of the lighhouse […]