
Introduction
In the previous entry of this tutorial series, we studied the lighthouse problem. The goal was to infer (or learn) the position of the lighthouse from observations of where the lighthouse’s light beam hits the floor. A schematic of the problem is presented below.
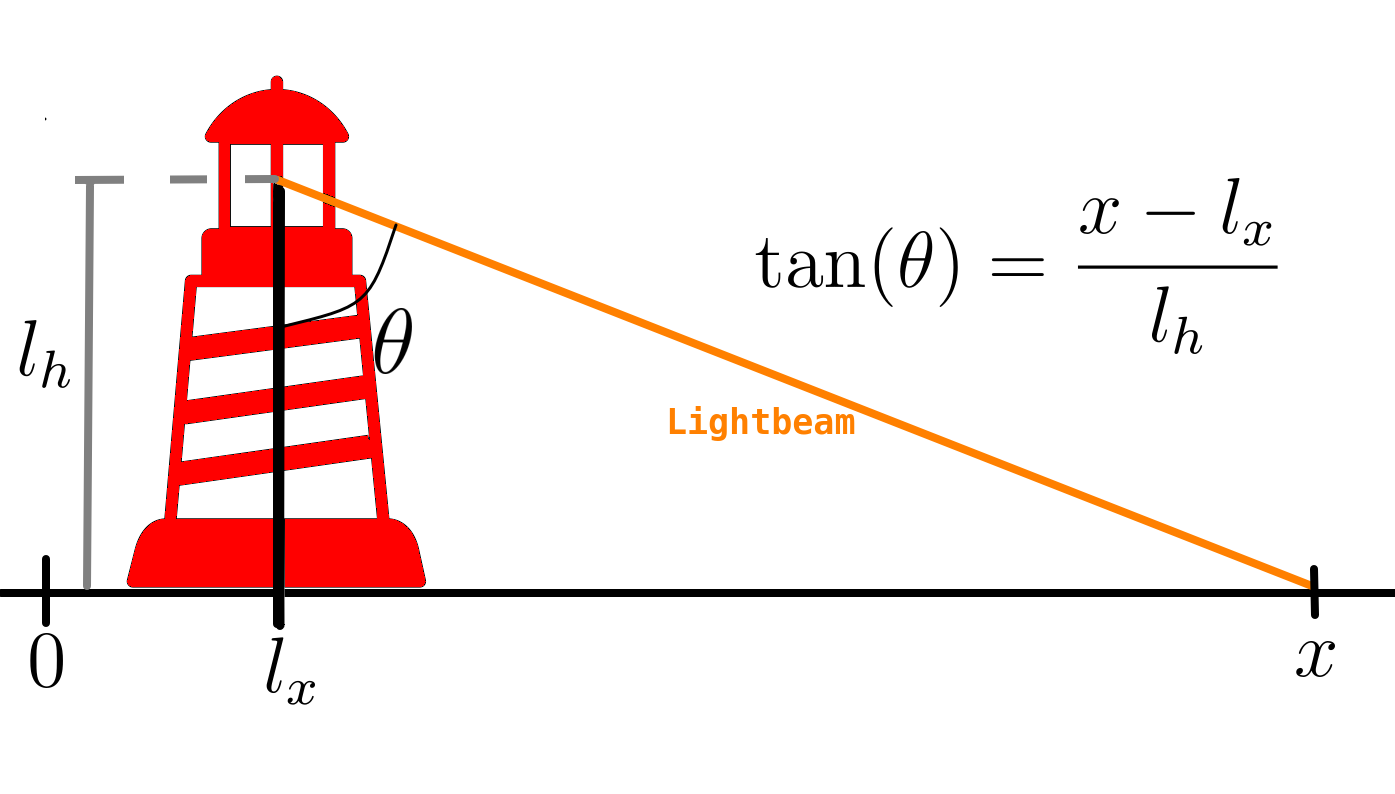
Following what was established on the previous post, let us generate synthetic data for the lighhouse problem. We sample uniformly in and obtain as
import numpy as np
from matplotlib import pyplot as plt
np.random.seed(42)
l_x,l_h = 0,1 #setting ground truth
th = np.pi*(np.random.rand(1024)-1/2) #sample theta
x = l_x +l_h*np.tan(th)
In the previous post we outline how to infer , the lighthouse horizontal position, assuming the height, is already known. However, the study of probabilities presented in that post does allow one to infer both and despite the fact that the observation is univariate.
The likelihood
This is possible by obtaining the conditional probability of a single point given and , as done in the previous blog post, which is given by
For a set of multiple data points obtained independently, the conditional probability, or likelihood, of the whole dataset is
Which, as in the previous blog post is expressed in terms of the logarithm for numerical stability, yielding
which can be calculated using the following piece of code
def log_like_2d(x,lx,lh):
LX,LH=np.meshgrid(lx,lh)
log_like = np.zeros_like(LX)
for xi in x:
log_like += np.log(LH)-np.log(np.pi)-np.log((xi-LX)**2+LH**2)
return log_like
Here we assume that and were given in a form of an (numpy) array representing all possible values. The choice to represent this way is better explained when we look into the prior.
Prior
In order to infer and we ought to invert the conditional probability using Bayes’ theorem:
with the prior, , chosen in a manner similar to the previous blog post
Or, in other words, the prior is uniform in and . For the purposes of later visualization we choose , but the results allow for much larger values.
L,H = 2.,2.
First let us generate the arrays for and :
lh_arr=np.linspace(0,H,101)+1e-12
lx_arr=np.linspace(-L/2,L/2,101)
this guarantees a good representation of the intervals and .
Posterior
Going back to the Bayes’ theorem (5), and substituting the prior (6) and likelihood (4) one obtains
Where , note that in (5) does not depend on or . As such, is calculares by ensuring that .
The following block of code gives a function to calculate the posterior (7)
def posterior(x,lx,lh):
L = log_like_2d(x,lx,lh)
L -= L.max()
P = np.exp(L) #unnormalized posterior
dlh,dlx = (lh[1]-lh[0]),(lx[1]-lx[0])
Z = P.sum()*(dlh*dlx) #normalization factor
P = P/Z
return P
Inference
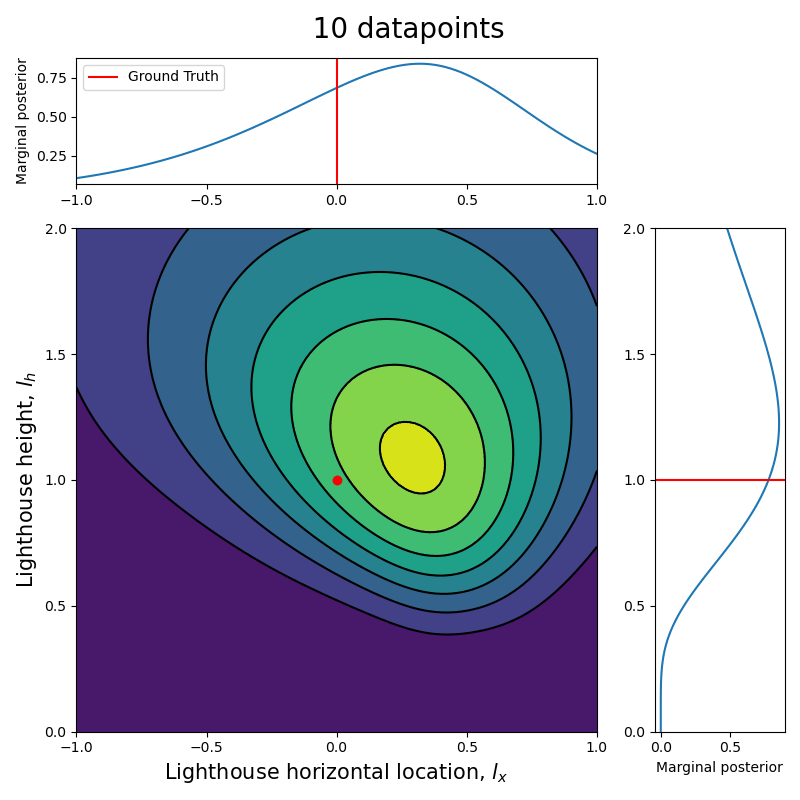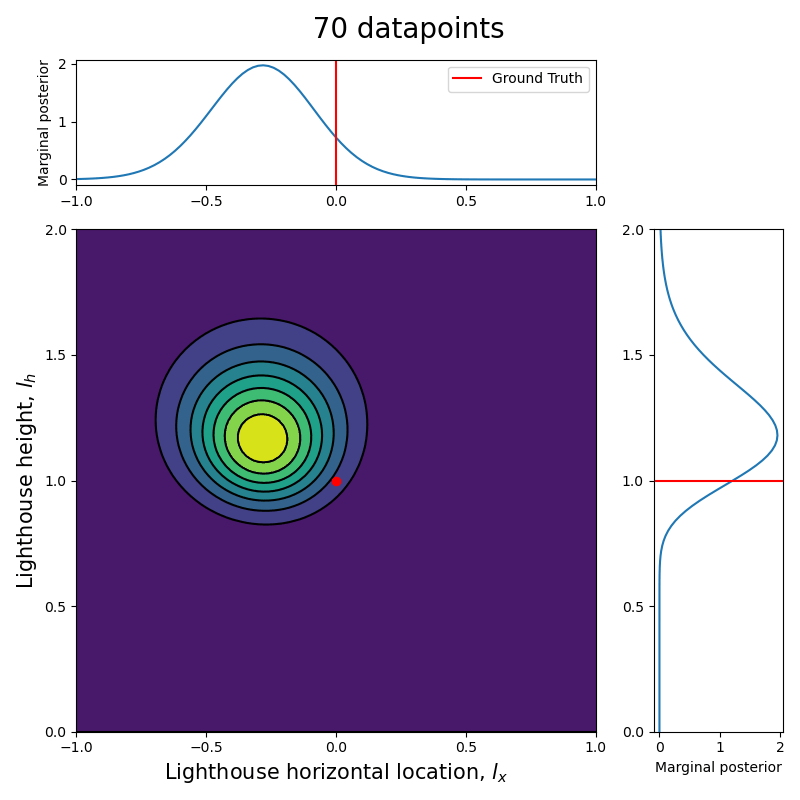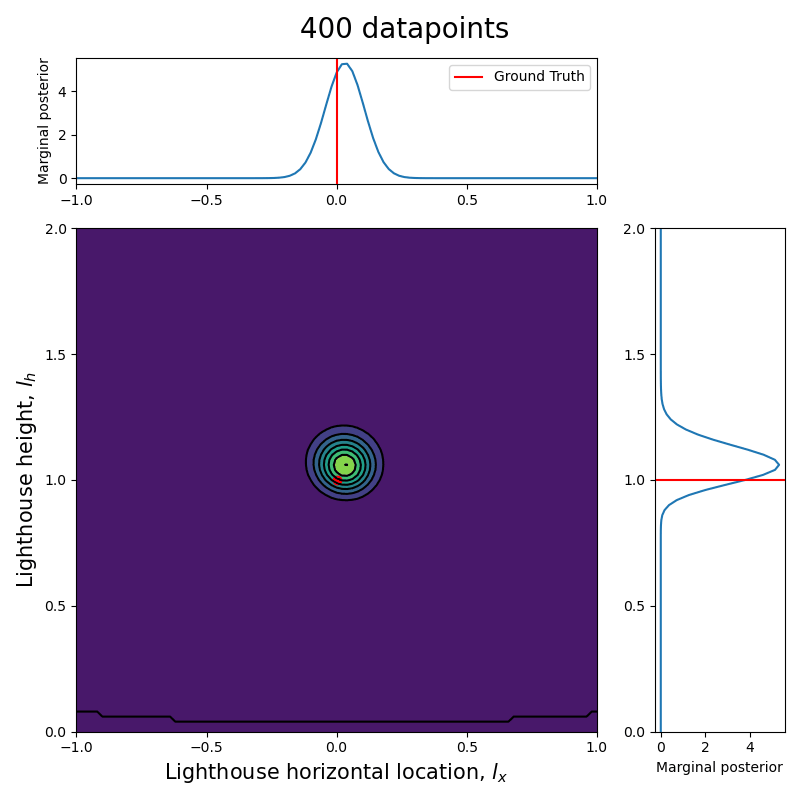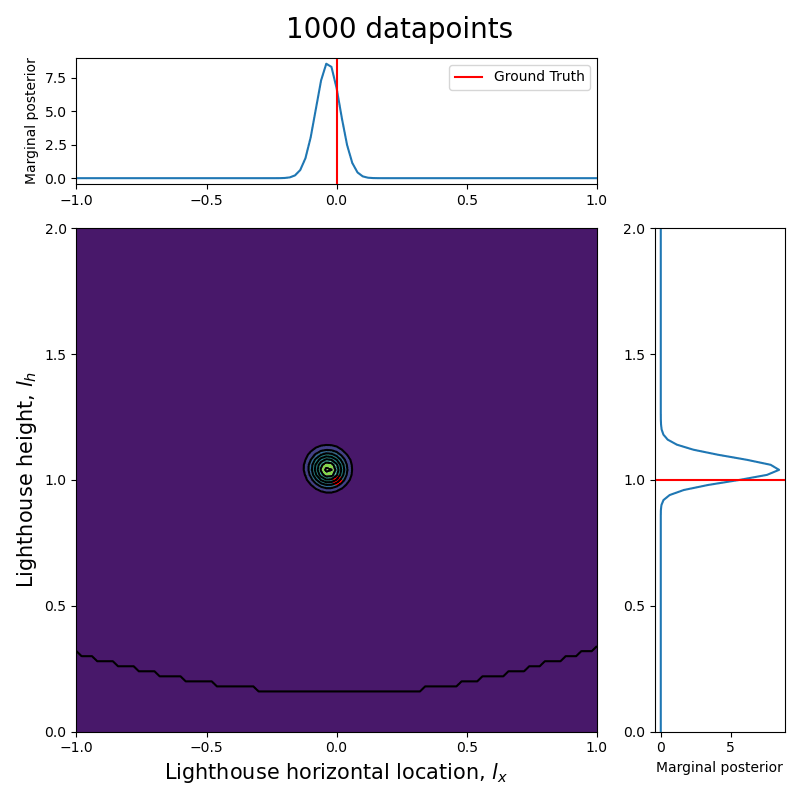
Now that we have the computational tools to calculate the posterior let us visualize how the posterior evolves with the number of datapoints.
Since we are talking about a two dimensional posterior, we present how it evolves with the number of datapoints through an animation (see the complete code in my GitHub repository).
#Removed data block, see notebook on GitHub for full code
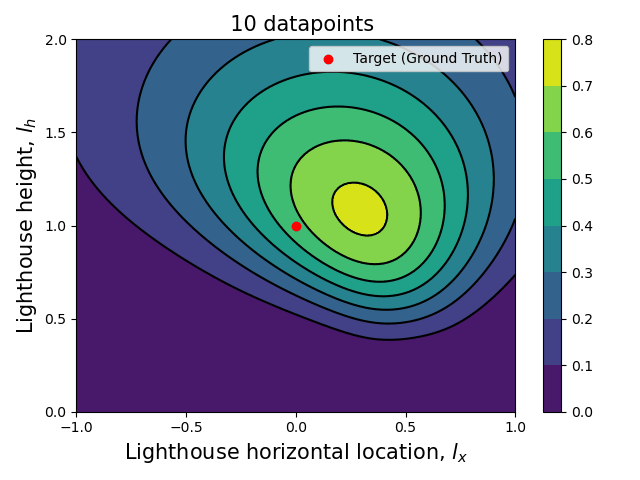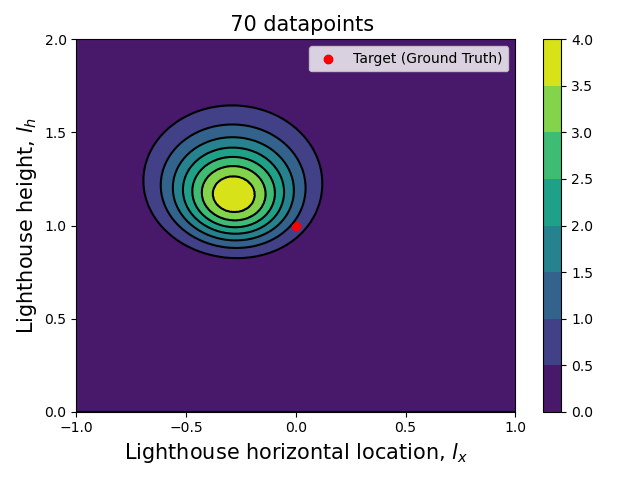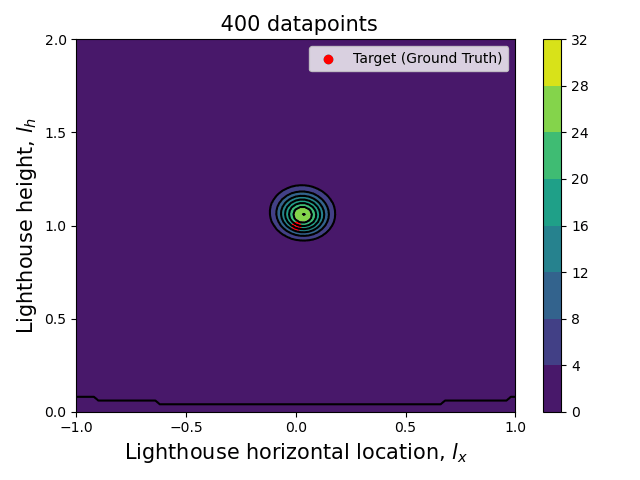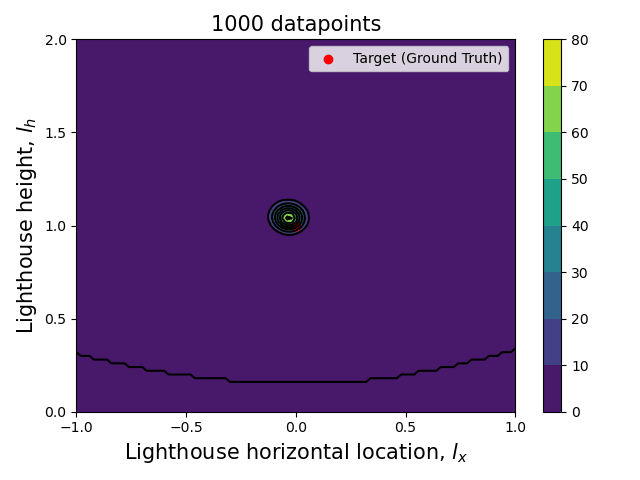
Marginal posterior distribution
While in the previous blog post we found the distribution for the lighthouse horizontal position, , assuming a known height, , here we obtain the distribution for both the and , denoted as . In order to obtain the posterior for only or only for we ought to sum (or integrate) over the probabilities of all possible value of the other parameter, that is:
In probability theory obtaining the probability for one parameter from the integral over the other parameters as above is often referred as marginalization. Moreover, in Bayesian language and are the marginalized posteriors while is the joint posterior.
It is important to notice that obtained above is conceptually different for what was done in the previous blog post. While there we considered that was already known here we cover all possible values of based on the posterior, which was learned from data.
In order to give a good visualization of how the marginal posterior for both and evolve with the total number of data points, we show an animation analogous to the previous one but also presenting the marginal posteriors parallel to their respective axis.
#Removed data block, see notebook on GitHub for full code
Here we can see clearly that, as the number of data points increase, the posterior (both the joint and each of the marginalized ones) tightens around the ground truth values.
Conclusion
Here we finish the overarching tutorial on Bayesian statistics. While future posts involving the topic will come, we presented a tutorial where:
- Bayesian statistics concurs with more naive methods of inference,
- The system is severely more complex and these naive methods fail, and
- The present post, where we went further into the previous problems to show how to learn multiple values even when the data available is single-valued.
Although this is the last entry of this tutorial series, more future posts related to the intricacies of probability and statistics in this blog. I hope this was instructive. Stay tuned.
